浪潮信息发布全新AI服务器方案,专为中小企业打造,仅靠CPU也能跑DeepSeek、QwQ
目前,大型模型技术正快速推广,但众多中小企业发现,使用GPU进行大模型运算的成本颇高。与此同时,CPU推理服务器以其独特优势,正逐步成为中小企业的理想选择。这一变化对行业生态产生了显著效应。
成本优势凸显
GPU服务器采购成本较高,给中小企业的硬件预算带来较大负担。而CPU推理服务器在成本方面具有明显优势,只需投入较少的硬件资金,就能达到更大系统内存的承载能力。以存储KV Cache为例,CPU推理服务器可轻松承载更多数据。这有助于降低数据交换次数。同时,它能在降低硬件成本的同时,提升推理效率。这对于企业节省运营成本具有积极作用。
高效的中等规模推理模型的应用,使得协同效应更加突出。在诸如企业知识库问答、文档撰写等具体应用场合,32B参数规模的模型只需CPU推理服务器即可实现本地部署。此方案在保证性能的同时,也确保了硬件成本的经济性和合理性,完全契合中小企业对成本控制的严格要求。
模型优化助力
业界多款32B推理模型不断进行技术创新,采纳了更高效的注意力机制、模型量化与压缩技术以及KV Cache的优化措施。这些技术大幅降低了模型的计算和存储要求,使得CPU推理服务器能够运行这些模型,并确保了其性能的优良。

该模型在应用领域展现出卓越性能。它不仅为企业的多样化场景提供坚实的功能保障,而且有效维持了硬件成本的合理水平。因此,中小企业无需在高端硬件上投入大量资金,即可获得高品质的大模型应用体验。
算力配置强大
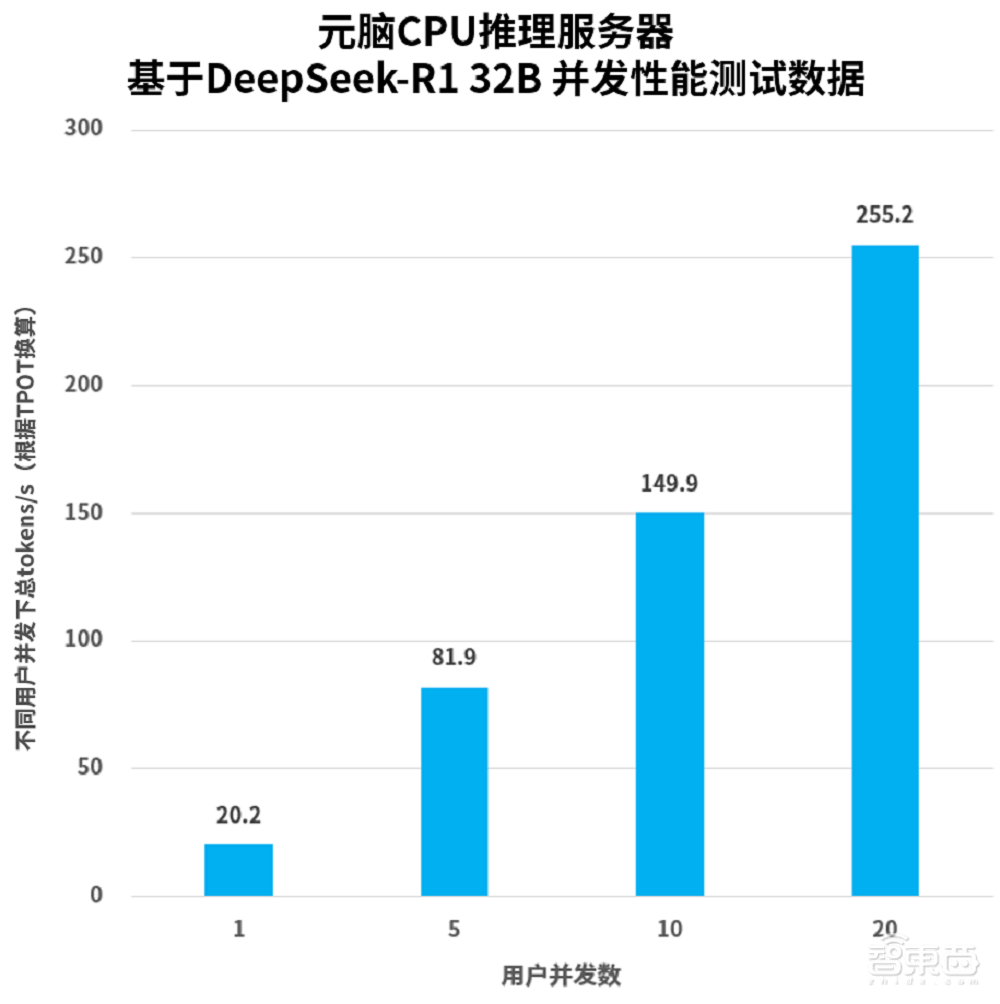
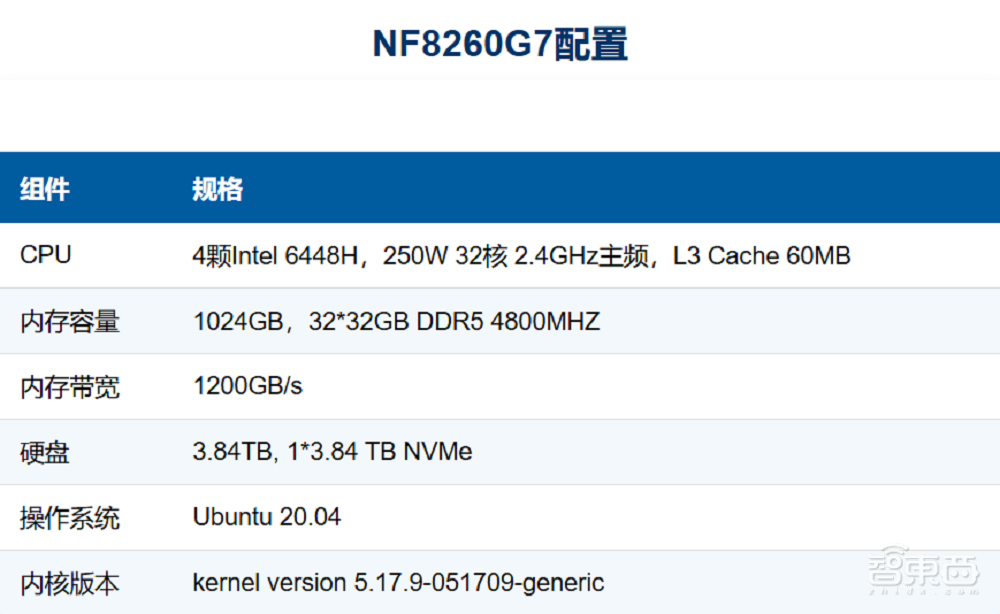
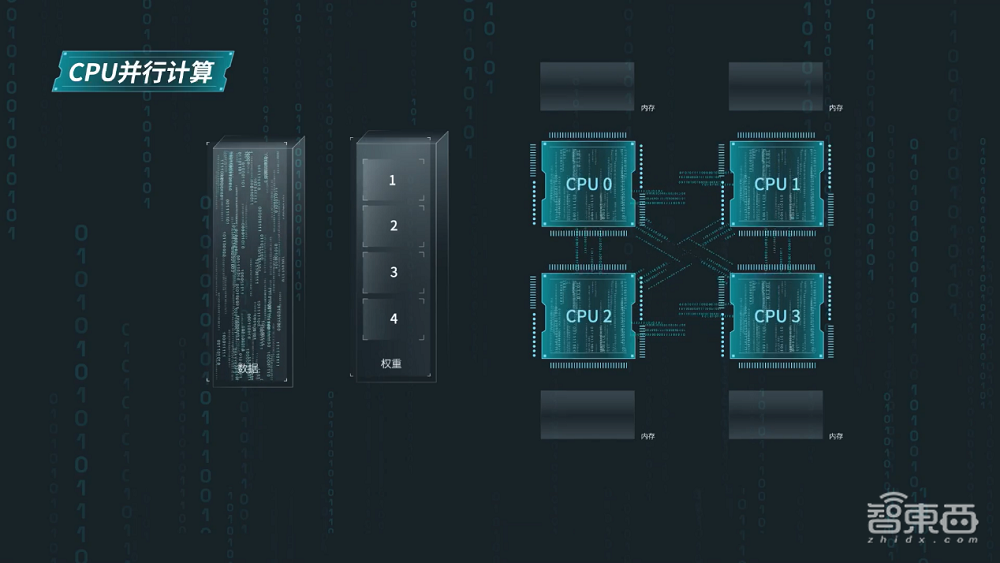
浪潮信息发布的元脑CPU推理服务器展现出卓越的算力性能。该服务器配备四颗32核心的英特尔至强处理器6448H。同时,它整合了AMX(高级矩阵扩展)AI加速技术。凭借这一坚实的算力基础,服务器为中等规模模型推理提供了可靠保障。因此,服务器能高效应对各种复杂任务。
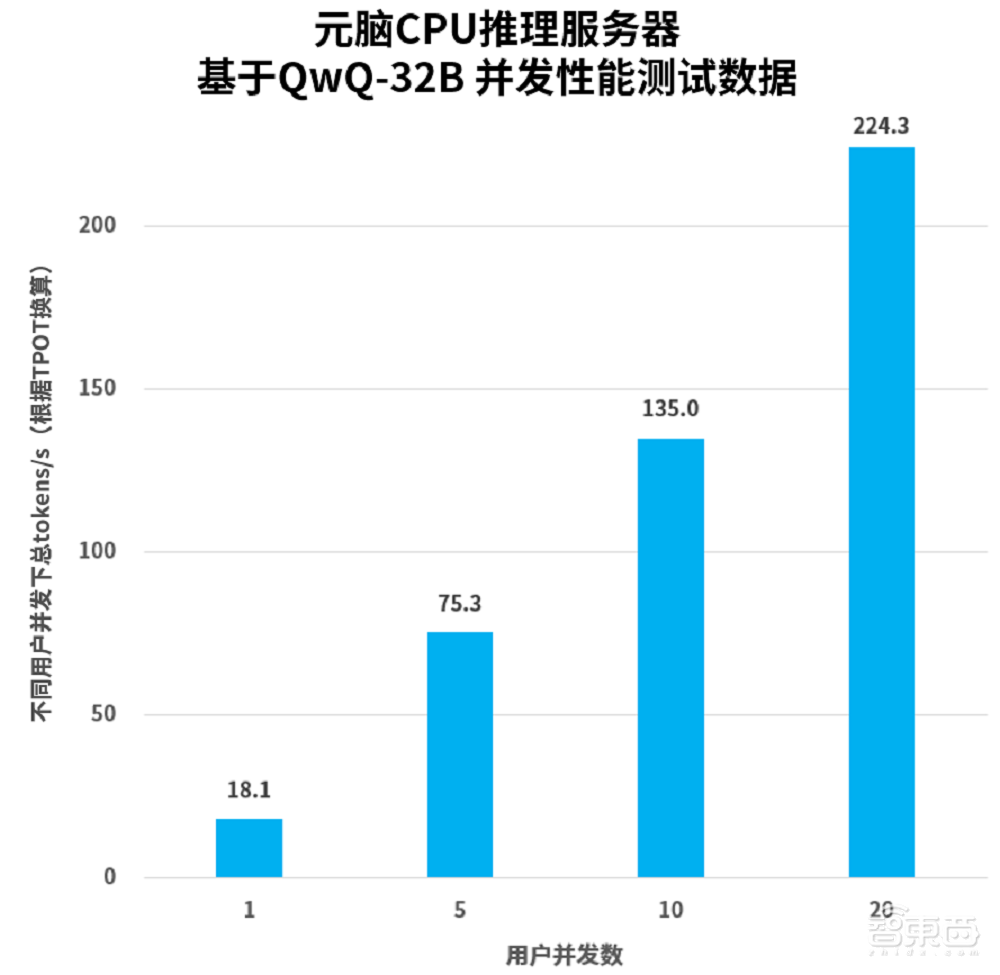
该服务器支持张量并行计算技术,这一技术能够实现数据的并行处理,大幅提高了计算效率。在运行时,它能够快速处理大型模型的输入数据,并迅速向企业输出推理结果,从而满足企业实际应用的需求。
算法优化升级
元脑CPU推理服务器对vLLM企业级大模型推理服务框架进行了精细调整和改进。该服务器通过应用张量并行和内存绑定技术,充分释放了CPU的计算能力和内存带宽。在多处理器并行计算环境下,其性能可大幅提升,最高可达四倍,从而显著提升了服务器的整体效能。
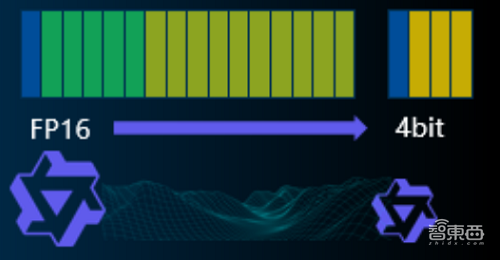
在解决内存带宽挑战的过程中,服务器采纳了AWQ(激活感知权重量化)技术。该技术实施后,解码任务的表现大幅提升,性能提升幅度高达一倍。同时,大型模型在保持高性能的同时,运行速度有所提升,资源使用量降低,对于中小企业追求的高效低成本应用目标,具有显著的实际意义。
模型适配灵活
浪潮信息打造的AI平台,其搭载的元脑CPU推理服务器,向用户提供了丰富多样的模型选项。用户可以根据具体需求,选择不同参数量的模型,例如全系模型、QwQ和Yuan等。这种灵活的选型机制,使得企业能够依据自身业务规模、数据量及应用场景等因素,挑选最合适的大模型,进而提高大模型应用的准确度和效率。
中小企业凭借其灵活的模型适应特性,在使用大型模型方面拥有更大的自主选择权。它们可根据业务需求的变化,灵活调整所使用的模型,无需更换硬件设备。这一做法显著降低了企业的运营费用和技术门槛。
综合优势显著
中小企业普遍不追求顶尖的AI性能或极高的并发处理能力,它们更偏好选择易于部署、管理和操作的初级AI推理服务。与GPU推理服务器相比,CPU推理服务器的生态系统更加健全,开发工具也更加完善。这使CPU推理服务器能够更顺畅地与企业现有的IT架构相结合,同时,其操作与维护过程也相对简便。
CPU推理服务器在通用性方面优于专门的AI硬件,如GPU服务器。当AI推理需求不旺盛时,该服务器仍能应对企业对其他通用计算任务的需求,比如数据库维护和ERP系统的运作。这一特性显著提高了硬件资源的使用效率,为中小企业带来了切实的经济收益。
这些优势预示着CPU推理服务器有望成为中小企业大规模模型应用的主流选择。我们热切期待您的宝贵意见,同时恳请您为本文点赞和分享,以共同追踪科技领域的最新动态。