研究人员以黑神话·悟空为平台,提出 VARP 智能体框架迎战 GPT-4o、Claude 3.5
GPT-4o、 3.5都来迎战
研究人员以《黑神话·悟空》为研究平台,一共定义了12个任务,75%与战斗有关。

他们构建了一个人类操作数据集,包含键鼠操作和游戏截图,一共1000条有效数据。
每个操作都是由原子命令的各种组合组成的序列。原子命令包括轻攻、闪避、重攻击、回血等。

然后,他们提出了VARP智能体框架。
主要包含动作规划系统和人类引导轨迹系统。
其中动作规划系统由情境库、动作库和人类引导库组成,利用 VLMs 进行动作推理和生成,引入分解特定任务的辅助模块和自我优化的动作生成模块。
人类引导轨迹系统利用人类操作数据改进智能体性能,对于困难任务,通过查询人类引导库获取相似截图和操作,生成新的人类引导动作。
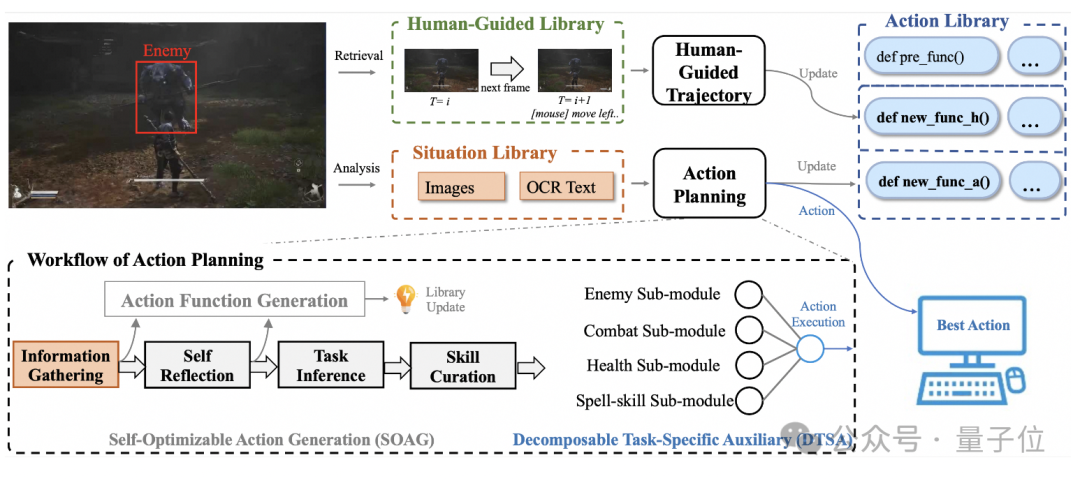
同时VARP还包含3个库:情景库、动作库和人工引导库。
这些库中存储了agent自我学习和人类指导的内容,可以进行检索和更新。
动作库中,“def ()”表示动作计划系统生成的新动作,“def ()”表示人导轨迹系统生成的动作。”def ()”代表预定义的动作。
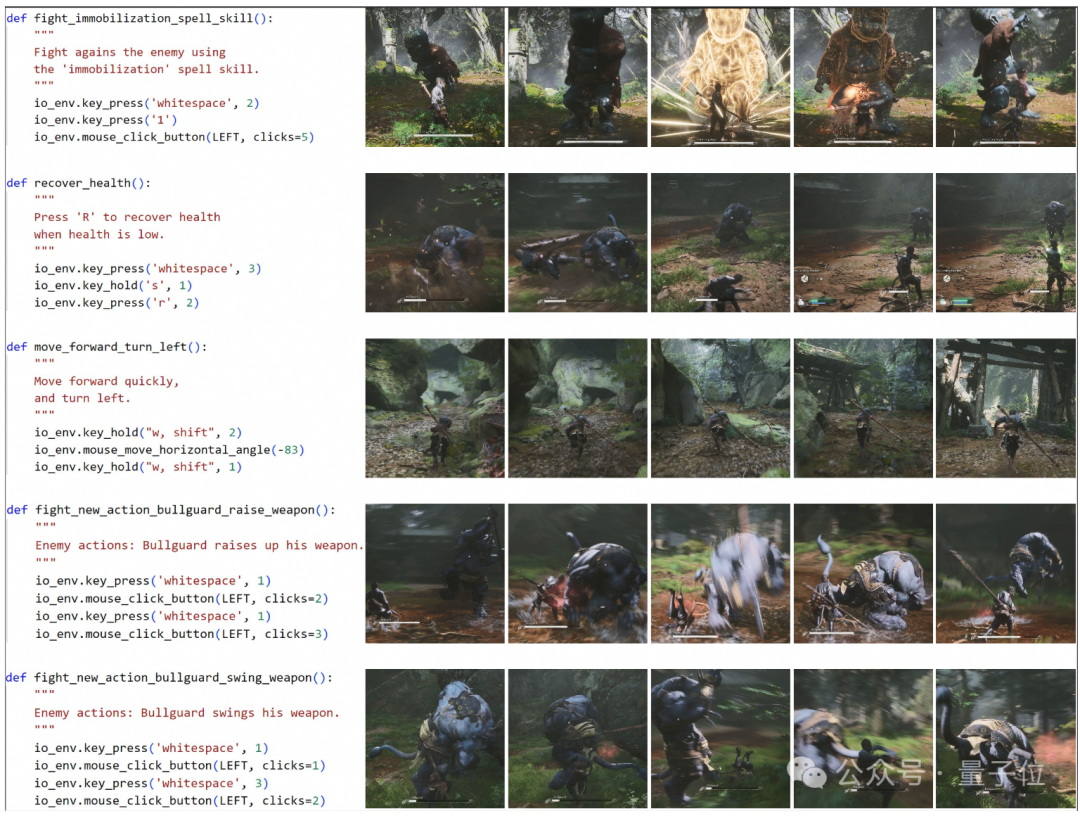
动作案例研究和相应的游戏截图。第一行和第二行中的操作是预定义的函数。第三行动作由人工制导轨迹系统生成。
SOAG会在玩家角色与敌人的每次战斗互动后总结第四行和第五行中的新动作,并将其存储在动作库中。
框架分别使用了GPT-4o(2024-0513版本)、 3.5 和 1.5 Pro。
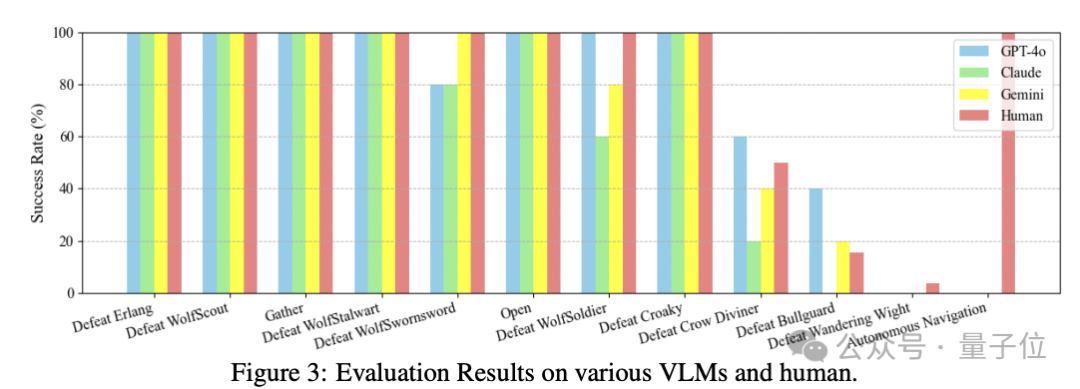
对比人类和AI的表现结果,可以看到小怪部分AI们的表现达到人类玩家水平。
到了牯护院时, 3.5 败下阵来,GPT-4o胜率最高。
但是对于新手玩家普遍头疼的幽魂,AI们也都束手无策了。
另外研究还提到,由于VLMs推理速度受到限制,是无法实时输入每一帧画面的。它只能间隔输入关键帧,这也会导致AI在一些情况下错过boss攻击的关键信息。
以及由于游戏中没有明确的道路引导且存在很多空气墙,在没有人类引导下,智能体也不能自己找到正确的路线。
如上研究来自阿里团队,一共有5位作者。

后续相关代码和数据集有发布计划,感兴趣的童鞋可以蹲下。
One More Thing
AI打游戏并不是一个新鲜事了,比如AI基于强化学习方法打《星际争霸II》已经可以击败人类职业高手。
利用强化学习方案,往往需要输入大量对局。商汤此前训练的DI-star(监督学习+强化学习),就用了“16万场录像”和“1亿局对战”。
但是纯大模型也能打游戏,还是很出乎意料的。在本项研究中,数据集中的有效数据为1000条。









