AIGC前沿研究:医生智能体可实现自我进化
原创 库珀 学术头条
本周值得关注的大模型 / AIGC 前沿研究:
清华团队提出“智能体医院”:医生智能体可实现自我进化
清华、智谱AI 团队推出无限超分辨率模型 Inf-DiT
具有 3D 理解能力的语言-图像模型
清华、智谱AI 团队推出代码评测基准
美团提出视频生成模型 ,采用 Mamba- 架构
注意力驱动的免训练扩散模型效率提升
IBM 推出开源代码大模型
AWS 团队提出基于目标的幻觉基准
“文生视频”新研究:多场景文生视频的时间对齐字幕
:高效文本驱动图像风格迁移的状态空间模型
想要第一时间获取每日最新大模型热门论文?
点击“阅读原文”,获取「2024 必读大模型论文」合集(包括日报、周报、月报,持续更新中~)。
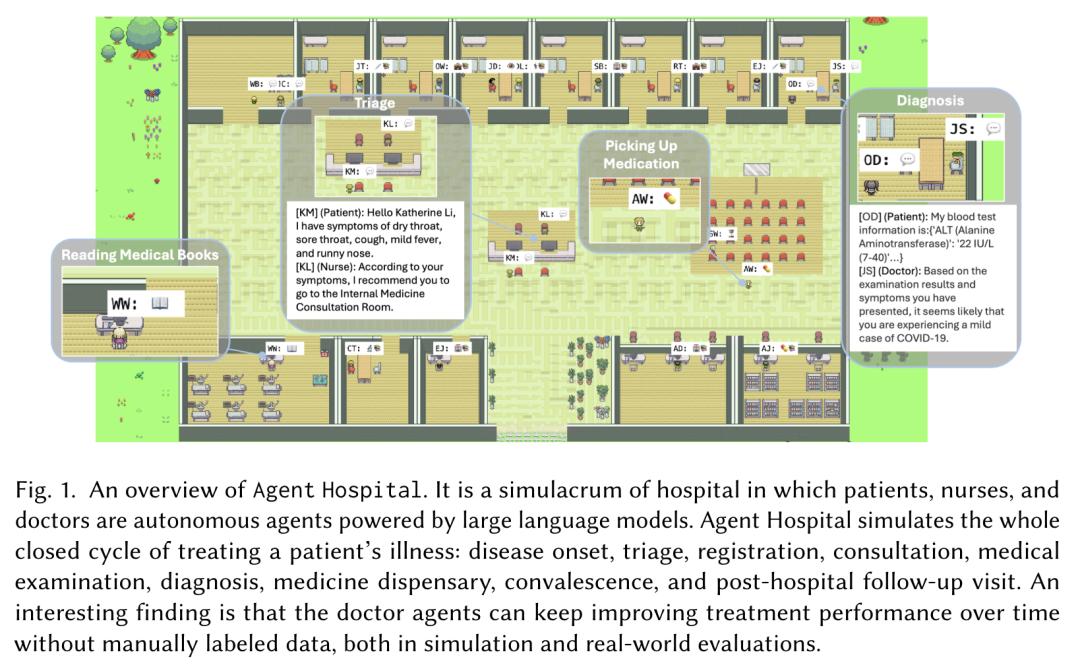
1.清华团队提出“智能体医院”:医生智能体可实现自我进化
在这项工作中,来自清华大学的研究团队提出了一种名为“智能体医院”(Agent )的模拟医院,它可以模拟治疗疾病的整个过程。其中,所有病人、护士和医生都是由大型语言模型(LLM)驱动的自主智能体。
该研究的核心目标是让医生智能体学会如何在模拟环境中治疗疾病。为此,研究团队提出了一种名为 -Zero 的方法。由于仿真系统可以根据知识库和 LLM 模拟疾病的发生和发展,医生智能体可以不断从成功和失败的病例中积累经验。
模拟实验表明,医生智能体在各种任务中的治疗效果都在不断提高。更有趣的是,医生智能体在“智能体医院”中获得的知识适用于现实世界的医疗保健基准。在治疗了约一万名患者后(现实世界中的医生可能需要花费两年多的时间),进化后的医生智能体在涵盖主要呼吸系统疾病的 MedQA 数据集子集上达到了 93.06% 的准确率。
论文链接:
2.清华、智谱AI 团队推出无限超分辨率模型 Inf-DiT
近年来,扩散模型在图像生成方面表现出了卓越的性能。然而,由于在生成超高分辨率图像(如 4096*4096)的过程中内存会二次增加,生成图像的分辨率往往被限制在 1024*1024。
在这项工作中,来自清华和智谱AI 的研究团队提出了一种单向块( block)注意力机制,其可以在推理过程中自适应地调整内存开销,并处理全局依赖关系。在此模块的基础上,他们采用 DiT 结构进行上采样,并开发了一种无限超分辨率模型,能够对各种形状和分辨率的图像进行上采样。
综合实验表明,这一模型在生成超高分辨率图像方面达到了机器和人工评估的 SOTA 性能。与常用的 UNet 结构相比,这一模型在生成 4096*4096 图像时可以节省 5 倍以上的内存。
论文链接:

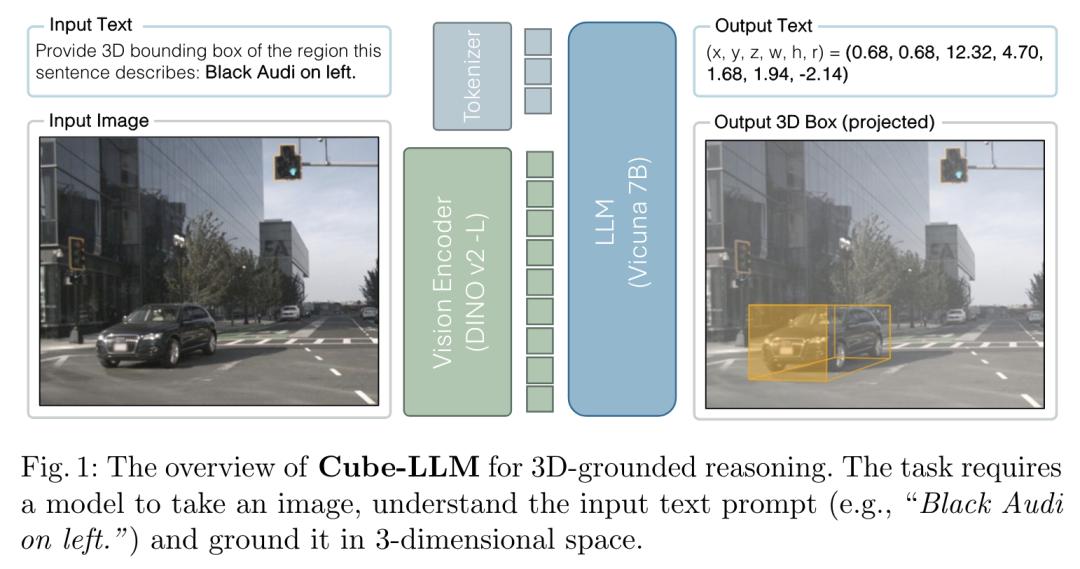
3.具有 3D 理解能力的语言-图像模型
多模态大型语言模型(MLLMs)在各种 2D 视觉和语言任务中表现出了惊人的能力。来自德州大学奥斯汀分校、英伟达的研究团队将 MLLM 的感知能力扩展进了 3D 空间的图像基准()和推理。
他们首先开发了一个大规模的 2D 和 3D 预训练数据集——LV3D,该数据集将现有的多个 2D 和 3D 识别数据集结合在一个共同的任务表述下:作为多轮问题解答;然后,他们提出了一种名为 Cube-LLM 的新型 MLLM,并在 LV3D 上对其进行了预训练。研究表明,纯粹的数据缩放可以产生强大的 3D 感知能力,而无需特定的 3D 架构设计或训练目标。
另外,Cube-LLM 具有与 LLM 相似的特性:1)Cube-LLM 可以应用思维链提示,从 2D 上下文信息中提高 3D 理解能力;2)Cube-LLM 可以遵循复杂多样的指令,并适应多种输入和输出格式;3)Cube-LLM 可接受视觉提示,如专家提供的 2D box 或一组候选 3D box。
室外基准测试表明,Cube-LLM 在 3D 基础推理 数据集和复杂驾驶场景推理 数据集上的表现,明显优于现有基准,分别比 AP-BEV 高出 21.3 分和 17.7 分。此外,Cube-LLM 还在 MLLM 基准(如用于 2D 基础推理的 )以及视觉问题解答基准(如用于复杂推理的 VQAv2、GQA、SQA、POPE 等)中显示出具有竞争力的结果。
论文链接:
项目地址:
4.清华、智谱AI 团队推出代码评测基准
大型语言模型(LLM)在为生产活动生成代码方面表现出强大的能力。然而,目前的代码合成基准,如 、MBPP 和 DS-1000,主要面向算法和数据科学的入门任务,不能充分满足现实世界中普遍存在的编码挑战要求。
为了填补这一空白,来自清华大学和智谱AI 的研究团队提出了自然代码基准(,简称 NCB),这是一个具有挑战性的代码基准,旨在反映真实编码任务的复杂性和场景的多样性。
据介绍,NCB 由 402 个 和 Java 中的高质量问题组成,这些问题都是从在线编码服务的自然用户查询中精心挑选出来的,涵盖 6 个不同的领域。考虑到为真实世界的查询创建测试用例异常困难,他们还提出了一个半自动化管道,从而提高测试用例构建的效率。与人工解决方案相比,其效率提高了 4 倍多。
他们在 39 个 LLM 上进行的系统实验发现, 分数接近的模型之间在 NCB 上的性能差距仍然很大,这表明我们对实际代码合成场景缺乏关注,或者对 进行了过度优化。另一方面,即使是性能最好的 GPT-4 在 NCB 上的表现也远远不能令人满意。
论文链接:
地址:

5.美团提出视频生成模型 ,采用 Mamba- 架构
在这项工作中,来自美团的研究团队提出了一种采用 Mamba- 架构、用于视频生成的潜在扩散模型——。 采用空间-时间注意力进行局部视频内容建模,采用双向 Mamba 进行全局视频内容建模,计算成本低。
综合实验评估表明,在基准性能方面, 与当前基于 和 GAN 的模型相比具有很强的竞争力,可获得更高的 FVD 分数和效率。此外,他们还观察到所设计模型的复杂度与视频质量的改善之间存在直接的正相关关系,这表明 具有出色的可扩展性。
论文链接:
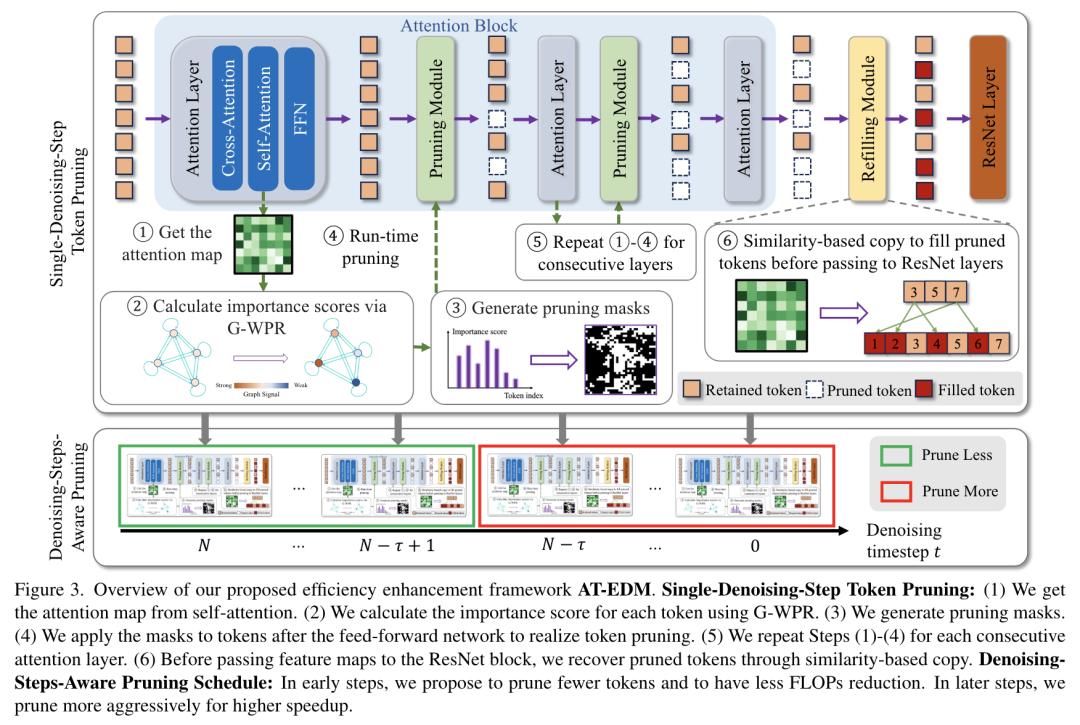
6.注意力驱动的免训练扩散模型效率提升
扩散模型(DMs)在生成高质量和多样化的图像方面表现出优越的性能。
然而,这种卓越的性能以昂贵的架构设计为代价,特别是在领先模型中大量使用了 模块。现有工作主要采用再训练流程来提高数据挖掘效率。这在计算上是昂贵的,且不太可扩展。
为此,来自普林斯顿大学和 Adobe 的研究团队提出了注意力驱动的免训练高校扩散模型(AT-EDM)框架,其利用注意力图来执行冗余 Token 的运行时修剪,而不需要任何再训练。具体来说,对于单步去噪修剪,他们开发了一种新的排序算法—— 通用加权页面排序(G-WPR),从而识别冗余的 Token,以及一种基于相似性的方法去恢复卷积操作的 Token。此外,他们还提出了一种去噪步骤感知的剪枝(DSAP)方法,来调整不同去噪时间步的剪枝预算,从而获得更好的生成质量。
广泛的评估表明,AT-EDM 在效率方面优于现有技术(例如,与 XL 相比,节省了 38.8% 的 FLOPs 和高达 1.53 倍的加速),同时保持与完整模型几乎相同的 FID 和 CLIP 分数。
论文链接:
地址:
7.IBM 推出开源代码大模型
经过代码训练的大型语言模型(LLM)正在彻底改变软件开发过程。为了提高人类程序员的工作效率,越来越多的代码 LLM 被集成到软件开发环境中,而基于 LLM 的智能体也开始显示出自主处理复杂任务的前景。要充分发挥代码 LLM 的潜力,需要具备广泛的能力,包括代码生成、修复错误、解释和维护资源库等。
在这项工作中,IBM 团队提出了用于代码生成任务的纯解码器 系列代码模型,这些模型是用 116 种编程语言编写的代码训练而成的,由大小从 30 亿到 340 亿个参数不等的模型组成,适用于从复杂的应用现代化任务到设备内存受限用例等各种应用。
对一整套任务的评估表明,在现有的开源代码 LLM 中, 代码模型的性能始终处于领先水平。另外, 代码模型系列针对企业软件开发工作流程进行了优化,在一系列编码任务(如代码生成、修正和解释)中表现出色。此外,团队已在 2.0 许可下发布了所有 代码模型,供研究和商业使用。
论文链接:
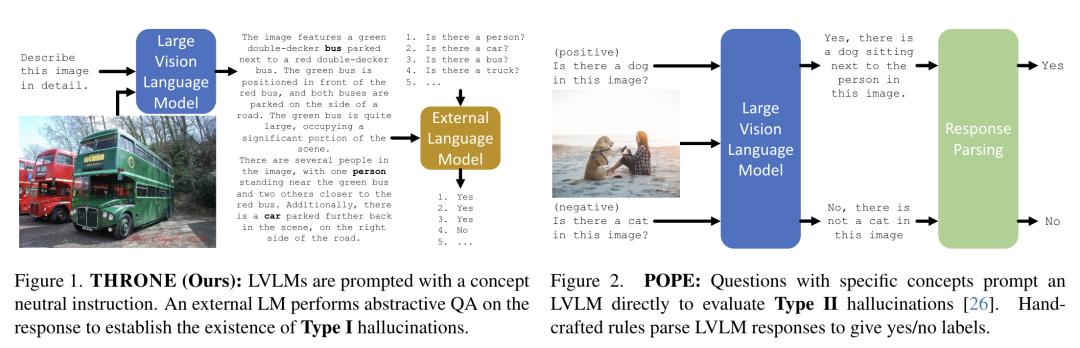
8.AWS 团队提出基于目标的幻觉基准
在大型视觉语言模型(LVLM)中减少幻觉仍然是一个未解决的问题。目前的基准并没有解决开放式自由回答中的幻觉问题, 即“第一类幻觉”,相反,其关注的是对非常具体的问题格式做出反应的幻觉——通常是关于特定对象或属性的多项选择反应——即“第二类幻觉”。此外,此类基准通常需要外部 API 调用模型,而这些模型可能会发生变化。
在实践中,来自 AWS 和牛津大学的研究团队发现,减少第二类幻觉并不会导致第一类幻觉的减少,相反,这两种形式的幻觉往往互不相关。为了解决这个问题,他们提出了 ,这是一个基于对象的新型自动框架,用于定量评估 LVLM 自由形式输出中的第一类幻觉。
他们使用公共语言模型来识别 LVLM 反应中的幻觉,并计算相关指标。通过使用公共数据集对大量最新的 LVLM 进行评估,他们发现,现有指标的改进并不会导致第一类幻觉的减少,而且现有的第一类幻觉测量基准并不完整。最后,他们提供了一种简单有效的数据增强方法,从而减少第一类和第二类幻觉,并以此作为强有力的基准。
论文链接:
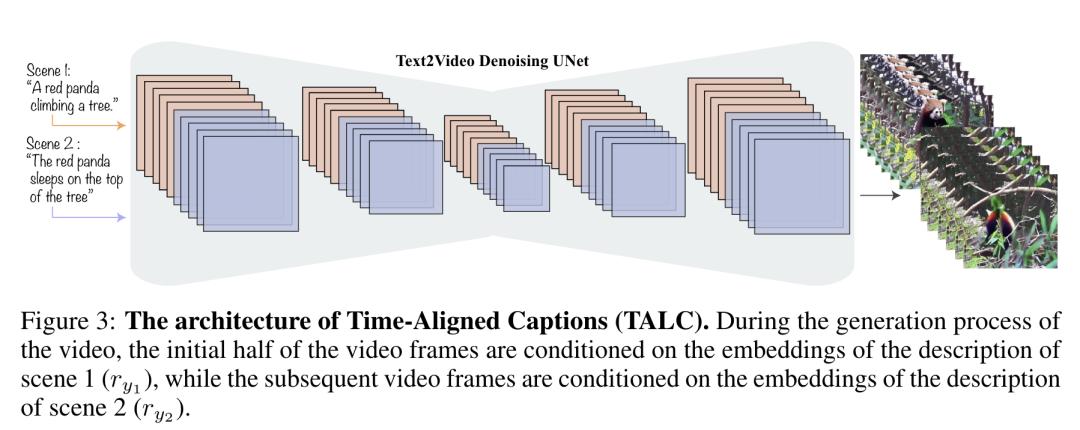
9.“文生视频”新研究:多场景文生视频的时间对齐字幕
文生视频(T2V)模型可以在文本提示的条件下生成高质量的视频。这些 T2V 模型通常产生单场景视频片段,描述执行特定动作的实体(比如,一只小熊猫爬树)。然而,生成多场景视频是非常重要的,因为它们在现实世界中无处不在(比如,一只小熊猫爬上树,然后睡在树顶上)。
为了从预训练的 T2V 模型生成多场景视频,来自加州大学洛杉矶分校和谷歌的研究团队提出了时间对齐字幕(TALC)框架,增强了 T2V 模型中的文本条件作用机制,从而识别视频场景和场景描述之间的时间对齐。例如,他们用第一个场景描述(一只小熊猫在爬树)和第二个场景描述(小熊猫睡在树顶上)的表示对生成视频的早期和后期场景的视觉特征进行条件约束。T2V 模型可以生成符合多场景文本描述的多场景视频,并在视觉上保持一致(如实体和背景)。
此外,他们使用 TALC 框架用多场景视频-文本数据对预训练的 T2V 模型进行微调。研究表明,用 TALC 微调的模型在总分数上比基线方法高出 15.5 分。
论文链接:
地址:
10.:高效文本驱动图像风格迁移的状态空间模型
来自帝国理工学院、芬兰奥卢理工大学和戴尔的研究团队提出了一种有效的图像风格迁移框架——,其能够将文本提示翻译为相应的视觉风格,同时保留原始图像的内容完整性。
现有的文本引导样式化需要数百次训练迭代,并且需要大量的计算资源。为加快这一过程,他们提出了一种条件状态空间模型 ,用于有效的文本驱动图像风格迁移,按顺序将图像特征与目标文本提示对齐。为了增强文本和图像之间的局部和全局风格一致性,他们提出了掩码和二阶方向损失来优化风格化方向,将训练迭代次数显著减少5次,推理时间显著减少3次。
广泛的实验和定性评估证实,与现有的基线相比,所提出方法达到了 SOTA。
论文链接:










