LoRA:大型语言模型的低阶适配,微调模型的热门方法

简介
当涉及到大型语言模型时,微调可能是人们讨论最多的技术方面的内容之一。大多数人都知道,训练这些模型是非常昂贵的,需要大量的资本投资;所以,看到我们可以通过采用现有的模型并用自己的数据对模型进行微调,从而创建一个具有自己特色的模型,这的确是一件令人兴奋的事情。
当前,已经存在多种方法可以对模型进行微调,但目前最流行的方法之一是论文《LoRA:大型语言模型的低阶适配》()中讨论的LoRA方法(Low Rank ,即低阶适配,缩写为“LoRA”)。
在我们深入研究LoRA背后的机制之前,我们需要先来了解一些矩阵有关的背景知识和微调机器学习模型的一些基础内容。
矩阵相关背景术语
实际上,所有的机器学习模型都将其权重存储为矩阵形式。因此,了解一些线性代数知识有助于获得对正在发生的事情的直觉认识。
从一些最基础的内容开始,我们可以创建一个如下图所示的由行和列组成的矩阵:
当然,行、列或两者都很多时,矩阵所占用的数据就越多。有时,当行和/或列之间存在某种数学关系时,我们就可以采取一些措施,使得存储这种矩阵所需的空间进一步减少。类比一下的话,这类似于一个函数所占用的空间比它所代表的所有坐标点要小得多。
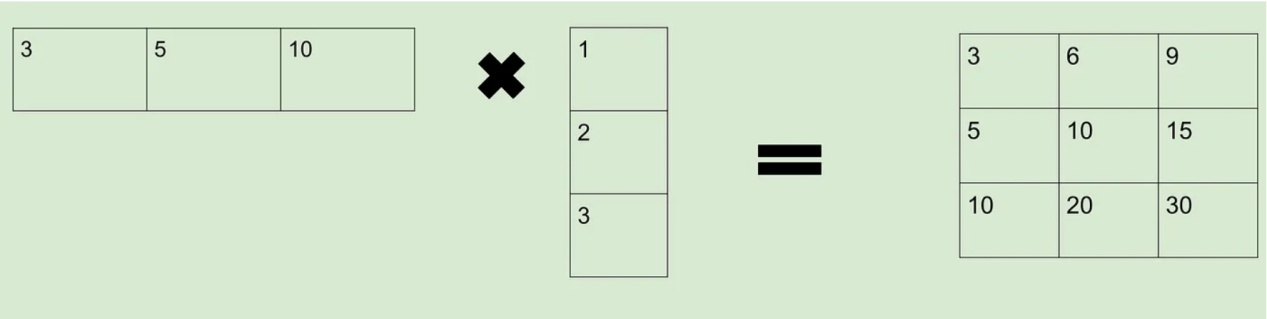
请参阅下面的示例,了解可以缩减为仅剩下1行的矩阵。这表明原始的3x3矩阵的秩为1。

因此,当一个矩阵可以像上面那样被约简时,我们说它的秩比不能这样被约简的矩阵的秩低。任何秩较低的矩阵都可以扩展回较大的矩阵,如下所示:
微调知识
要对模型进行微调,您需要一个高质量的数据集。例如,如果你想微调汽车聊天模型,那么你需要一个包含数千个关于汽车的高质量对话的数据集。
创建数据后,您将获取这些数据并在模型中运行它们,以获得每个数据的输出。然后,将此输出与数据集中的预期输出进行比较,并计算两者之间的差异。通常,使用类似交叉熵的函数(突出显示2个概率分布之间的差异)来量化这种差异。
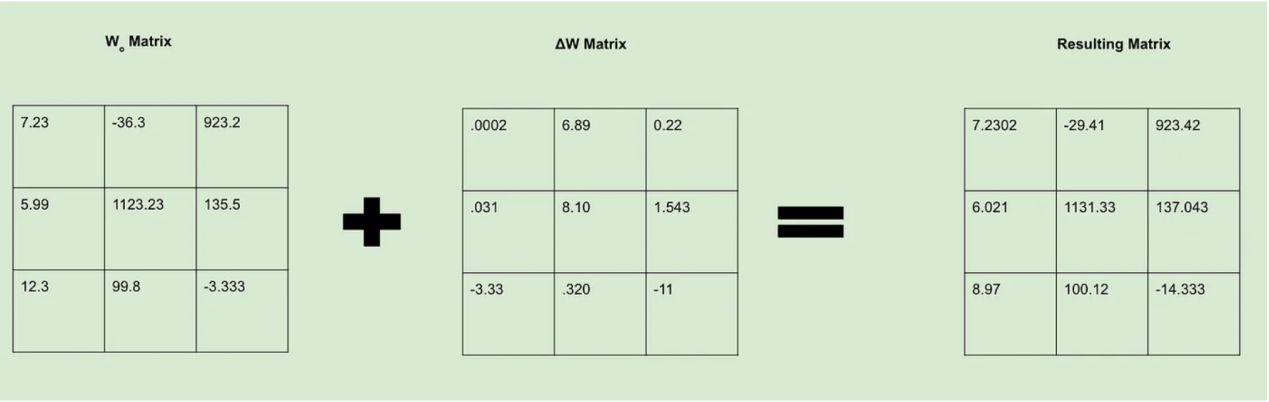
现在,我们接受损失值并使用它来修改模型权重。我们可以把这一过程看作是创建一个新的ΔW矩阵,其中包含我们想让Wo矩阵知道的所有变化。计算出权重后,我们就可以决定如何改变这些权重值,以便其在我们的损失函数中给出一个更好的结果。为此,我们想办法通过反向传播来调整权重。
如果有足够兴趣的话,我还会单独写一篇关于反向传播背后的数学逻辑的博客文章,因为这是很有趣的事情。目前,我们可以简单地说,计算权重变化所需的计算成本非常高昂。
LoRA方法
总体来看,LoRA技术始终围绕着一个关键的假设:虽然机器学习模型的权重矩阵具有较高的秩,但在微调过程中创建的权重更新矩阵具有较低的内在秩。换言之,我们可以用一个比从头开始训练所需的矩阵小得多的矩阵来微调模型,而不会看到任何重大的性能损失。
因此,我们可以这样设置我们的基本方程:
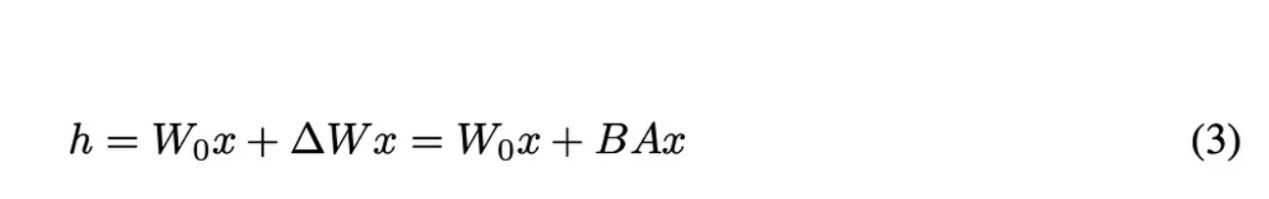
原论文中的方程3
让我们来分析一下上面方程中的每一个变量的含义。其中,h代表微调后的权重值。Wo和ΔW与以前的含义相同,但在此,作者创造了一种定义ΔW的新方法。为了找到ΔW,作者构造了两个矩阵:A和B。其中,A是一个与Wo具有相同列维度并开始填充随机噪声的矩阵,而B具有与Wo相同的行维度并初始化为所有元素均为0的矩阵。这些维度是很重要的,因为当我们将A和B相乘时,它们将创建一个维度与ΔW完全相同的矩阵。
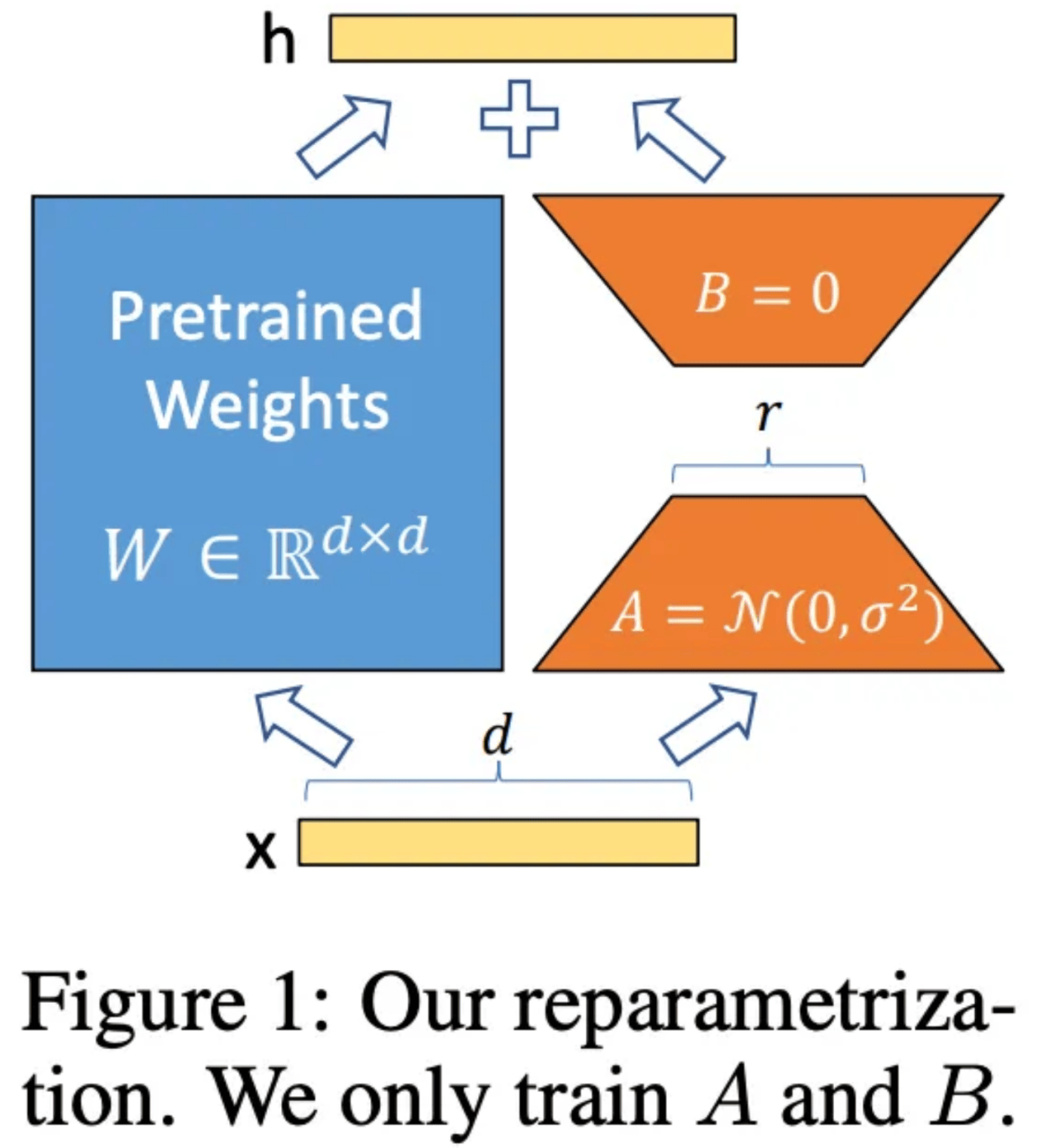
原论文中的图1
在微调过程中,矩阵A和B的秩是一个超参数集。这意味着,我们可以选择秩1来加快最大训练量(同时仍更改为Wo),或者增加秩大小,从而以更大的成本提高性能。
使用LoRA进行微调
现在,回到我们以前的图像,让我们看看当使用LoRA技术时有关计算是如何发生变化的。
请记住,微调意味着创建ΔW矩阵,该矩阵包含我们对Wo矩阵的所有更改。作为一个简单示例,假设A和B的秩均为1,维度为3。因此,我们得到了如下图片:
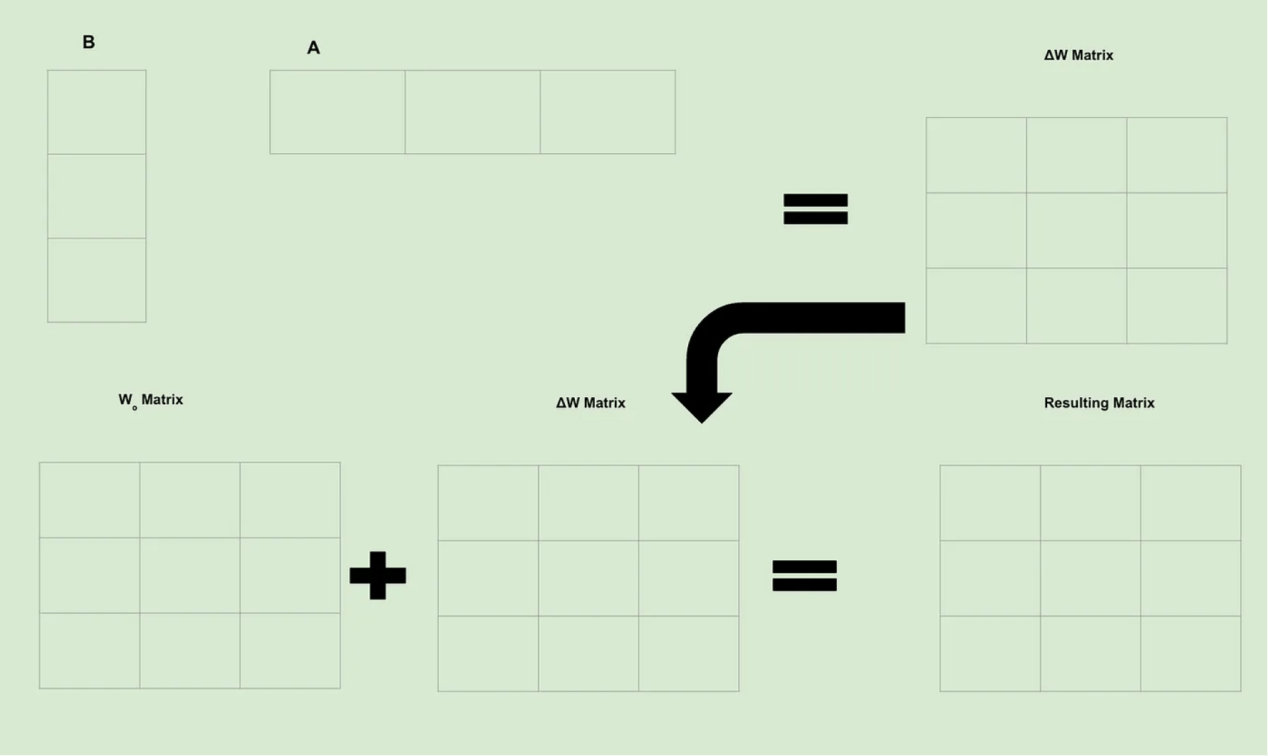
因为矩阵中的每个单元都包含一个可训练权重;所以,我们立即就可以明白为什么LoRA的功能如此强大:我们已经从根本上减少了需要计算的可训练权重的数量。因此,虽然寻找单个可训练权重的计算通常保持不变,但是因为我们计算的次数要少得多,所以我们节省了大量的计算和时间。
结论
当前,LoRA技术已经成为微调大数据模型的行业内的标准方法。即使是拥有巨大资源的公司也认为LoRA是改进其模型的一种具有成本效益的方法。
展望未来,一个有趣的研究领域就是如何找到这些LoRA矩阵的最优秩。现在的计算方案中,它们作为超参数的方式使用,但是如果存在一个理想的超参数的话,就可以节省更多的时间。此外,由于LoRA仍然需要使用高质量的数据;因此,另一个颇有前途的研究领域就是寻找LoRA方法的最佳数据组合。
虽然流入人工智能的资金是巨大的,但是,高支出并不总是意味着总会有高回报。一般来说,公司的钱花得越长远,就越能为客户创造更好的产品。因此,作为一种极具成本效益的改进产品的方式,LoRA理所当然地成为了机器学习领域的固定投资的一部分。
因此,现在正是一个激动人心的发展时期……









