IBM AIU NorthPole 处理器:低延迟高能效的大型语言模型推理设备
摘要
对于一个30亿参数的LLM,一个带有16个IBM AIU 处理器的研究原型推理设备提供了巨大的28,/秒的系统吞吐量和低于1 ms /token(每用户)延迟,而16个卡在一个紧凑的2U外形上仅消耗672 W。专注于低延迟和高能效,当 (12 nm)与一套GPU (7 / 5 / 4 nm)在各种功耗下进行比较时,在最低的GPU延迟下,提供72.7个更好的能效指标(token/s/ W),同时提供更好的延迟。
介绍
大型语言模型(LLMs)已经在不同的AI任务中取得了显著的性能基准,例如通过提供代码建议来协助编程,在标准化测试中表现出色,以及帮助文章,博客,图像和视频的内容创建。
在LLMs的大规模部署中,特别是在人工智能的大规模部署中,出现了两个主要且相互冲突的挑战,即:能源消耗和响应延迟。
首先,由于LLM在训练和推理方面都需要大量的能源资源,因此需要一个可持续的未来计算基础设施来实现其高效和广泛的部署。随着数据中心碳足迹的扩大,以及它们越来越受到能源限制,数据中心的能源效率变得越来越重要。根据世界经济论坛的报告:
“目前,数据中心环境碳足迹主要分成两部分:训练占20%,推理占80%。随着人工智能模型在不同领域的发展,对推理及其环境足迹的需求将会升级。”
其次,许多应用程序,如互动对话和自主工作流,需要非常低的延迟。在给定计算架构内,降低延迟可以通过降低吞吐量来实现,但这会导致能效下降。借用一句经典的系统格言进行改述:
“吞吐量问题可以通过资金解决,而延迟问题则更为复杂,因为光速是固定的。”(改述自[10],将“带宽”替换为“吞吐量”。)
GPU可以通过使用较小的批量大小来实现更低的延迟,但代价是吞吐量和能效的下降。此外,GPU分片通过在多个GPU上使用数据并行性来减少延迟,但同样牺牲了能效。无论是否分片,GPU似乎都遇到了延迟下限的硬性限制。GPU在能效与延迟之间的权衡如图1所示。
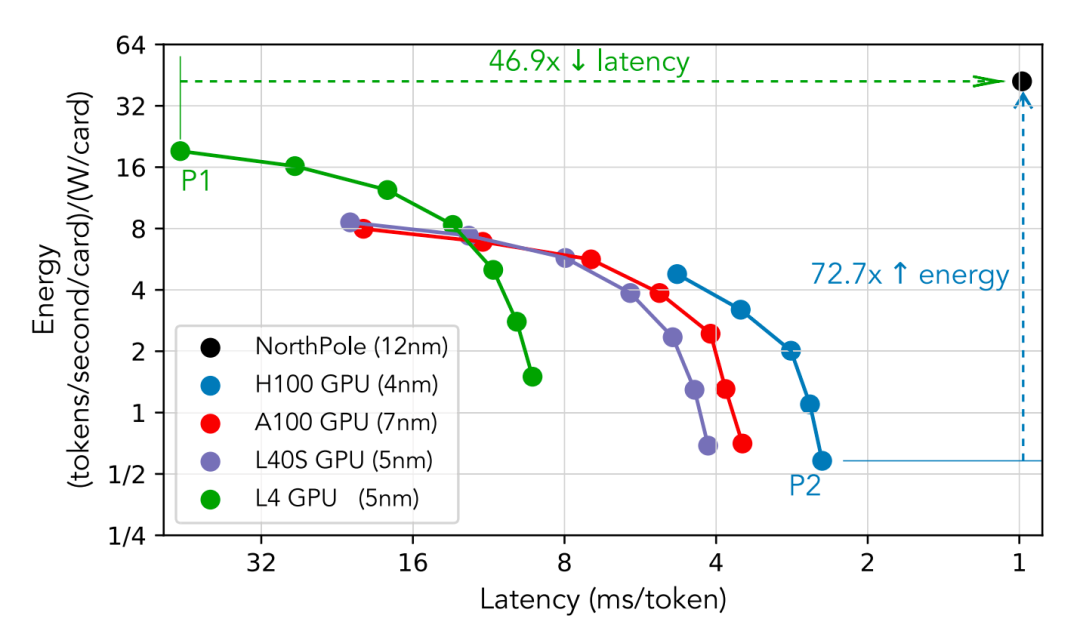
图1:(12 nm)在能量和系统延迟指标上相对于当前最先进的GPU(7 / 5 / 4 nm)的性能,其中系统延迟是每个用户所经历的总延迟。在最低的GPU延迟(H100,点P2)时,提供了72.7倍的更好能效指标( / / W)。在最佳的GPU能效指标(L4,点P1)时,则提供了46.9倍更低的延迟。
因此,本文所探讨的一个关键研究问题是如何同时实现低延迟与高能效这两个相互冲突的目标。
是一个推理加速器芯片和软件生态系统,从第一性原理共同设计,为神经网络推理提供卓越的效率。尽管并不是专门为LLM设计的,但令人惊讶的是,本文证明了新型架构可以实现低延迟、高能效的LLM推理(图1、图2和表1)。
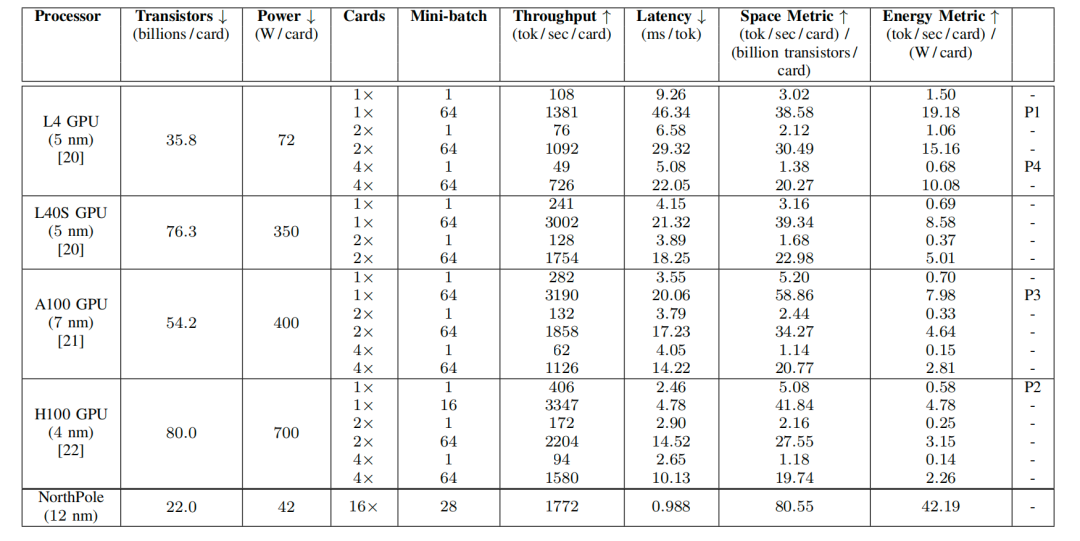
表 I:性能测量结果
测量了和GPU系统的性能,按每卡计算。对于每个指标,#表示越低越好,而"表示越高越好。对于 16卡设备,功耗按每卡测量,总系统吞吐量按16张卡进行划分。延迟通过所有16张卡进行测量。P1、P2、P3、P4分别指代图1和图2中标记的点,表示最高GPU能效指标、最低整体GPU延迟、最高GPU空间指标和最低能效GPU延迟。
本文的主要研究结果如下:
对于一个参数量为30亿的大型语言模型(LLM),其模型结构源自IBM -8B-Code-Base模型,并与Llama 3 8B和 7B[14]保持一致,本文展示了一种配备16个处理器的研究原型推理设备。
在绝对性能方面,该设备提供28,356 /sec的系统吞吐量,单用户延迟低于1毫秒,同时在2U机型下,16个卡的功耗为672瓦。
在相对性能方面,将12纳米的与一系列GPU(分别为7 / 5 / 5 / 4纳米的A100 / L4 / L40S / H100)在不同功耗下进行比较,可以从图2(a)和图2(c)中看出:在最低的GPU延迟(点P2)时,提供了72.7倍更好的能效指标( / / W)和15.9倍更好的空间指标( / / ),同时延迟仍低于2.5倍;在最佳GPU能效指标(点P1)时,提供了46.9倍更低的延迟和2.1倍更好的空间指标,同时仍提供2.2倍更好的能效指标;在最佳GPU空间指标(点P3)时,提供了20.3倍更低的延迟和5.3倍更好的能效指标,同时仍提供1.4倍更好的空间指标。
特别是,当将12纳米的与5纳米的L4 GPU进行可比功耗比较时,从图2(e)中可以看出,在最高的L4吞吐量(低于50毫秒每token,点P1)时,提供了46.9倍更低的延迟,同时吞吐量提高了1.3倍;而在最低的L4延迟(点P4)时,提供了36.0倍更高的吞吐量( / / card),同时延迟仍低于5.1倍。
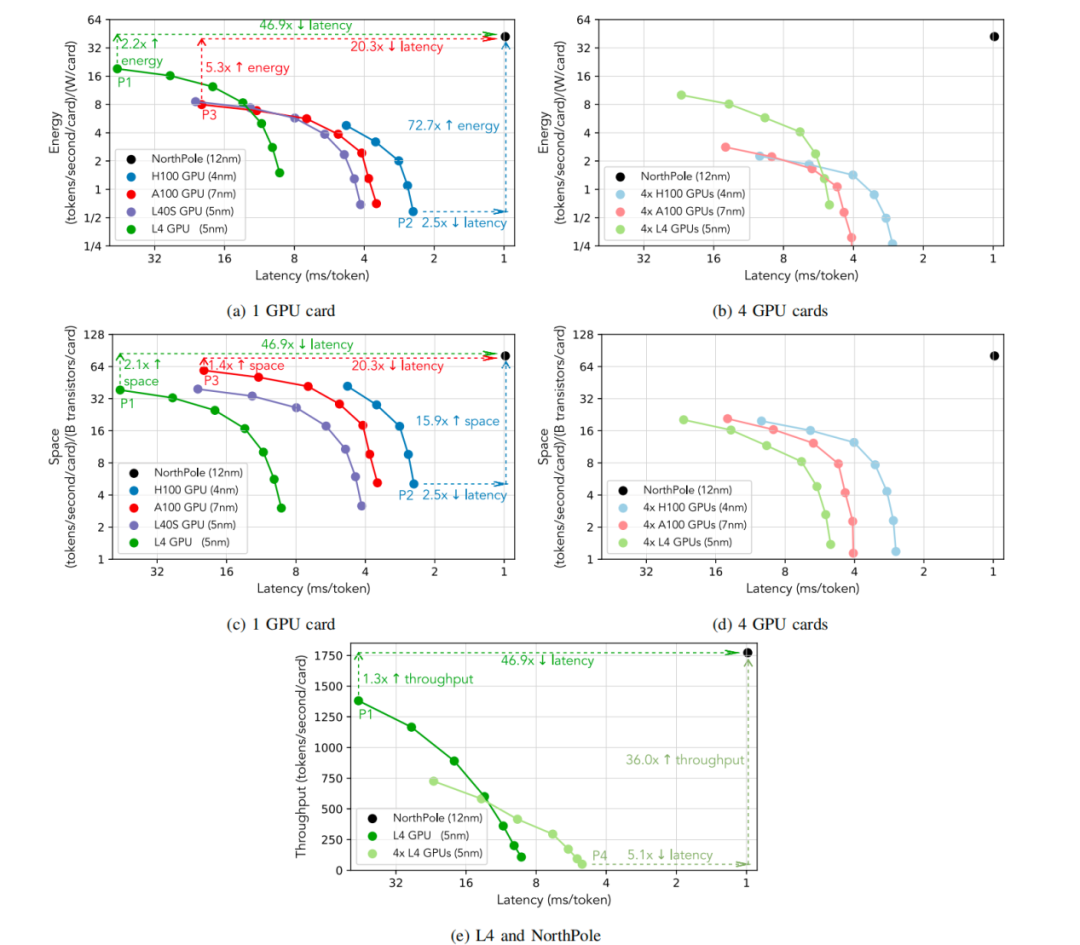
图2:(a)–(d)面板显示了12纳米的在能效、空间和系统延迟指标上相对于当前最先进的GPU(7 / 5 / 4纳米)的性能,其中系统延迟是每个用户所经历的总延迟。
面板(a)与图1相同,增加了点P3的标注。面板(a)和(c)使用单个GPU,而面板(b)和(d)使用分片技术,这可能降低延迟,但仅以牺牲能效和空间效率为代价。在最低的GPU延迟(H100,点P2)时,提供了72.7倍更好的能效指标( / / W)和15.9倍更好的空间指标( / / ),同时延迟仍低于2.5倍;在最佳GPU能效指标(L4,点P1)时,提供了46.9倍更低的延迟和2.1倍更好的空间指标,同时仍提供2.2倍更好的能效指标;在最佳GPU空间指标(A100,点P3)时,提供了20.3倍更低的延迟和5.3倍更好的能效指标,同时仍提供1.4倍更好的空间指标。
面板(e)显示了12纳米的在吞吐量( / / card)和系统延迟指标上相对于5纳米的L4 GPU的性能。在最低的L4延迟(点P4)时,提供了36.0倍更高的吞吐量;在最高的L4吞吐量(低于50毫秒每token,点P1)时,提供了46.9倍更低的延迟。用于计算每个能效指标的GPU功耗见表I。由于没有可用的仪器来测量不同批量大小的实际功耗,因此对所有批量大小使用相同的功率,这可能会低估能效指标,但定性的结果仍然成立。
架构
如图3所示,处理器采用12纳米工艺技术制造,拥有220亿个晶体管,面积为795平方毫米。其架构受到大脑的启发,经过针对硅的优化,源于十个互补的设计公理,涵盖计算、存储、通信和控制,使在标准AI推理任务中显著超越其他架构,即使是与更先进工艺技术制造的处理器相比也表现优异。
有关架构的详细公理,请参见[11],[12]。简而言之,将256个模块化核心排列在16×16的二维阵列中。每个核心包含一个向量-矩阵乘法器(VMM),在INT8、INT4和INT2精度下,每个核心每个周期分别执行2048、4096和8192次操作。核心计算还包括一个4路、32切片的FP16向量单元和一个32切片的激活函数单元。核心阵列总共有192 MB的SRAM,每个核心配备0.75 MB的SRAM。片上存储器与计算单元和控制逻辑紧密耦合,核心存储器与计算之间的总带宽为13 TB/s。此外,每个核心都有4096根导线在水平和垂直方向交叉,用于通过四个专用片上网络(NoCs)传递参数、指令、激活值和部分和。为了防止停顿,片上帧缓冲区配备32 MB的SRAM,将输入和输出数据的片外通信与核心阵列的片上计算解耦。

图3:处理器:硅片(左),裸片(中),封装模块(右)。
设备
已经在一个PCIe Gen3 × 8卡中进行了原型设计,如图4所示,其中16个卡安装在一台现成的2U服务器中,组成了一个研究原型推理设备,如图5所示。该服务器包含两颗Intel Xeon Gold 6438M处理器,每颗处理器具有32个核心和60 MB缓存,主频为2.2 GHz。系统还配备了512 GB的4800 MHz DDR5内存。每个服务器处理器连接有两条PCIe Gen5 × 16总线,提供总共256 GB/s的PCIe带宽(双向)。这四条总线通过PCIe桥接器扩展至系统的16个PCIe插槽,每个插槽上都安装了一个卡。这16个卡最大使用可用的256 GB/s PCIe带宽的一半。

图4: PCIe卡。

图5:研究原型设备的分解视图,展示了16个 PCIe卡的安装。卡可以通过标准的PCIe端点模型与主机进行通信,或者通过每个卡上的附加硬件功能直接、更加高效地彼此通信。
该系统运行Red Hat 8.9,使用内置的VFIO内核驱动,以便用户空间的软件能够管理硬件。系统使用IOMMU进行地址转换管理,并启用设备隔离和虚拟化等安全功能,以便使用虚拟机或容器技术运行应用程序。
每个卡通过驻留在每个卡上的DMA引擎接收和传输数据。这些DMA引擎独立工作,可以以多种方式同时接收和传输张量。第一种方法是标准的PCIe端点模型,主机程序通过DMA引擎从主机内存中读取输入,并在计算完成后将张量写回主机内存。第二种方法利用每个卡上的附加硬件功能,使卡可以通过PCIe直接相互通信,而无需进行主机内存之间的传输或在运行时进行额外的软件管理。通过直接的间通信,可以使更大的模型跨越多个芯片,同时减少通信延迟和由纯软件管理系统带来的开销。
将LLMs映射到设备
映射LLMs的策略,如图6所示,受到了三个关键观察的启发。首先,对于足够大的模型,整个变换器层可以使用INT4格式的权重、激活值和KV缓存完全适配在单个芯片的内存中(“w4a4”),而输出层则可以适配在两个芯片上。其次,如果权重和KV缓存完全驻留在芯片上,运行时只需在层间传输小型嵌入张量,这在PCIe Gen3 × 8的带宽范围内。第三,可以通过在现成服务器中安装16个 PCIe卡,轻松组装原型设备。
这暗示了一种策略,将每个变换器层映射到各自的卡上,采用GPipe风格的流水线并行性,并将输出层跨两个卡拆分,使用张量并行性,通过PCIe Gen3 × 8将层之间的嵌入张量发送。在推理过程中,一个用户请求的小批量(例如N个请求)被分成M个相等的微批量,并通过16个卡进行流水线处理。
虽然流水线并行性已在LLMs训练中得到利用(没有延迟限制),但在推理中的使用受限于减少每个流水线阶段的空闲时间或流水线气泡所需的大小批量。例如,有研究发现,高效训练要求微批量数M大约是流水线阶段数的四倍。小批量大小N受到以下因素的限制:(a)系统所需的每个token延迟,以及(b)用于存储整个小批量的KV缓存的可用内存。低延迟计算和13 TB/s的片上内存带宽使能够实现极低的每个token延迟,因此选择N时的限制因素是用于在芯片上存储整个KV缓存的内存。此外,我们发现微批量数M等于流水线阶段数足以使流水线空闲时间可忽略不计。
在本文报告的实验中,我们选择了N = 28的小批量大小,分为M = 14个相等的微批量,从而使每个卡计算的微批量大小为2。我们在如此小的批量大小下进行高效计算的架构设计选择是实现图1和表I中所示效率的关键。
LLM模型与训练方法
LLM模型
用于测试我们系统的模型基于开源的IBM -8B-Code-Base模型,这是一个具有80亿参数的变换器解码器,包含36个变换器层,隐藏层大小为4096,FFN中间层大小为14,336,注意力头数为32,使用分组查询注意力(GQA)的键值头数为8,词汇表大小为49,152。为了适应带有16个卡的单个服务器,我们使用了该模型的30亿参数版本,包含14个变换器层和一个输出层,量化为w4a4精度,但其他结构保持不变。
值得注意的是,这种模型配置在每层的基础上与Llama 3 8B[13]和 7B[14]相匹配,仅在层数、模型词汇表大小和使用的训练数据上有所不同。
完全精度准确性的训练
为了在量化后恢复原始模型的任务准确性,采用了以下程序来创建模型权重。首先,基于116种语言的1万亿个代码token,从头开始训练一个基线模型,使用全FP16精度,遵循[4]的配方。接下来,对基线模型的输出层权重和输入,以及SiLU激活进行了INT8量化,而所有其他权重、线性层输入和矩阵乘法输入则进行了INT4量化。最后,通过对来自训练数据的语言子集的进一步85亿个token进行量化感知训练,恢复后量化准确性,学习率为8×10⁻⁵,批量大小为128,采用LSQ算法。激活量化器的步长使用热启动进行训练,在训练的前250步中将学习率提升200倍,以帮助快速适应数据。
在GPU上运行的基准FP16模型和在上运行的量化模型在-上的精度为pass@10,误差在0.01以内(0.3001 GPU vs. 0.2922 。与-8B-Code-Base模型相比,整体训练被简化为专注于硬件性能表征,而不是推动任务准确性的界限。
运行时应用
在推理过程中,如图6所示,token由在主机CPU上运行的高度流水线化用户应用生成,该应用通过使用分词器和嵌入层将文本预处理为输入张量,将输入张量放入设备中的第一个卡,从设备的最后一个卡接收结果输出张量,使用解码器和反分词器对输出张量进行后处理,并将生成的token循环作为下一个输入。用户应用还负责用户界面以及提示预填充等更高级的优化。
为了将神经网络工作负载卸载到,用户应用调用具有简单API的用户空间运行时库,在初始化时配置卡的层权重和KV缓存,并在运行时发送和接收输入与输出张量。权重和KV缓存配置后保留在片上内存中,运行时无需从片外流式传输。运行时库还管理片上帧缓冲区,以防止核心因缺乏输入数据或输出数据接收方而停滞。中间张量在卡之间传递,无需主机干预,如第四节所述。
性能结果
16卡设备在30亿参数LLM上实现了28,/秒的吞吐量。该LLM的序列长度配置为2048(1024个提示长度,生成1024个token),解码器采用贪婪采样。
为了与GPU进行比较,我们测量了两款针对低功耗推理的GPU(L4 和 L40S)及两款针对高吞吐量训练的GPU(A100 和 H100)的单卡性能。所有系统均运行相同的LLM模型和配置,以w4a4精度运行,而GPU则以最佳的w4a16精度运行,因为据我们所知,没有可用的w4a4 CUDA核心。在我们的GPU实验中,我们利用了GPTQ量化模型,并使用vLLM(版本0.5.4)核心进行基准测试,以便与进行比较。使用GPTQ量化通过降低权重精度,同时保持可接受的准确性,为GPU提供了最佳的模型推理性能。此外,核心被用来优化矩阵运算,特别是在处理稀疏和密集矩阵乘法时。通过vLLM运行时的基准测试,使我们能够评估吞吐量和延迟,确保在给定硬件配置下的最佳模型性能。在多个GPU卡的实验中,采用与可用卡数相等的张量并行性,以有效获得通过的最小可能延迟。我们的实验表明,分片技术虽然减少了延迟,但导致GPU每卡的吞吐量下降。值得注意的是,的卓越性能主要源于其巨大的片上内存带宽,其次才是较低的精度。
表I显示了和GPU系统在每卡基础上的测量性能结果。基本指标包括吞吐量、延迟、空间和能量指标,定义如下。
对于输入提示的小批量生成的总token数为:
其中,MMM为微批量的数量,为单个用户生成的输出token数。系统吞吐量是响应输入提示的生成token总数( gen),除以处理提示所需的总时间,包括提示预填充时间( time)和token生成时间(token gen time):
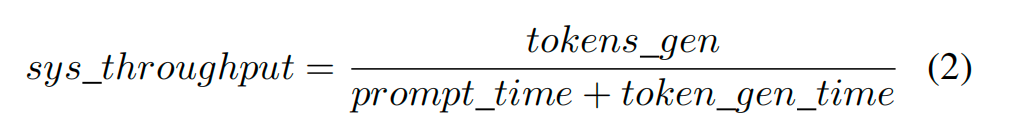
吞吐量以每卡为单位进行比较,方法是将系统吞吐量除以系统中处理卡的数量:
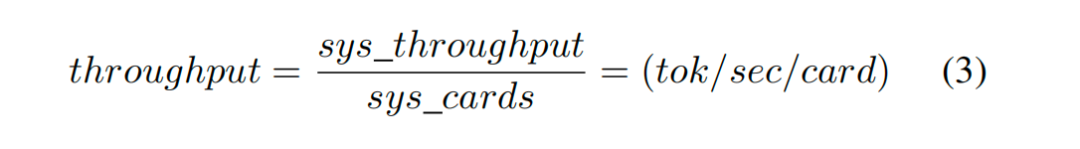
延迟是对特定用户生成输出token之间的平均时间的度量,它是嵌入token流经处理管道所需时间的总和,以及在生成token总数上平摊的提示预填充时间:
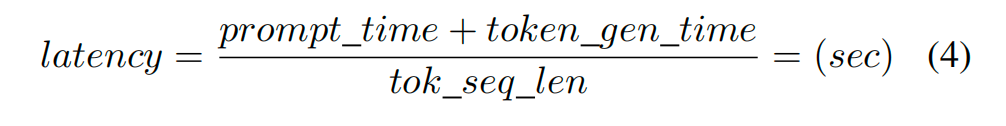
同样地,结合式1、2、4:
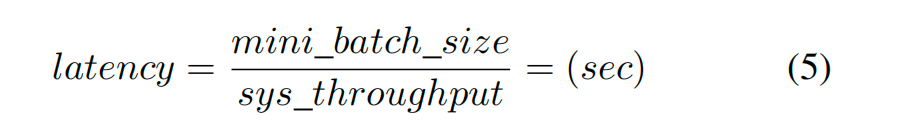
其中小批大小=小批大小注意,这是每个用户看到的系统延迟。
通过系统中的卡片数量进行规范化,我们扩展了[11]中定义的空间和能量指标,以便能够比较具有不同卡片数量的系统。由此产生的空间和能量指标是每张卡的吞吐量,分别由每张卡的处理器晶体管数量和每张卡的功率归一化:

如果系统吞吐量与系统中流水线卡的数量成比例地扩展,则卡的规范化将被抵消,使空间和能量指标与系统中卡的数量保持不变。通常,由于通信和同步开销,系统吞吐量在卡数量上呈次线性增长。
结论
我们提出以下贡献:
我们展示了一个多卡设备的研究原型。
我们证明了像LLM这样的大型神经网络模型可以有效地在多个处理器之间拆分,扩展了我们之前的工作,后者显示单个处理器在视觉推理任务(、Yolo-v4)上的表现优于其他架构。
我们证明了独特的架构非常适合LLM推理,使其在低延迟和高能效的双重目标上显著超越边缘和数据中心GPU。
由于设备必须作为一个整体使用,因此它对高吞吐量应用最为高效。
本初步论文为进一步研究能效优化、在相应更大设备上映射更大LLM、新的与架构协同优化的LLM模型,以及未来系统和芯片架构提供了一个跳板。