2018年,推出首款支持专用AI加速的PCGPU
今天在 Build 大会上公布了适用于 的全新 AI 性能优化和集成,以帮助用户充分发挥 RTX AI PC 和 RTX 工作站的性能。
大语言模型 (LLM) 可为生成式 AI 领域的一些全新应用场景提供支持。使用全新 R555 Game Ready 驱动,通过 ONNX (ORT) 和 提高大语言模型 (LLM) 的推理性能,带来至高可达 3 倍的性能提升。ORT 和 是在 PC 上本地运行AI模型的高性能工具。
WebNN 是一个供 Web 开发者部署 AI 模型的API,旨在允许 Web 应用程序和框架在客户端利用硬件来加速深度神经网络的推理,该 API 现可通过 实现 RTX 加速此外, 将支持 作为运行后端,使 开发者能在本地 上原生的训练和推理复杂的 AI 模型。 与 正在合作,在 RTX GPU 上进一步提升性能。
先进的 AI 平台可为全球超过 1 亿台 RTX AI PC 和工作站上的 500 多款应用和游戏提供加速支持。
RTX AI PC:游戏玩家、创作者和开发者可获得更强 AI 性能。
2018 年, 推出了首款支持专用 AI 加速的 PC GPU,即搭载 Core 的 RTX 20 系列 GPU。同年, 还推出了首款在 上得到广泛使用的 AI 模型 DLSS。 最新的 GPU 可提供高达 1,300 万亿次运算/秒的专用 AI 性能。
未来几个月内,搭载 RTX GPU 的 11 AI PC 将与大家见面,支持 提供的全新功能,为游戏玩家、创作者、发烧友和开发者提供更强性能,以应对要求严苛的本地 AI工作负载。
对于使用 RTX AI PC 的游戏玩家而言, DLSS 最多可将帧率提升至原来的 4 倍,而 ACE 则可通过 AI 驱动的对话、动作和语音使游戏人物变得栩栩如生。
对于内容创作者而言,RTX 可为 Adobe 、 和 等应用中的 AI 辅助生产工作流提供支持,以自动执行繁琐的任务并简化工作流。从 3D 降噪和加速渲染到文本生成图像及视频,这些工具可帮助艺术家将自己的构想变为现实。
对于游戏 而言,基于 平台构建的 RTX Remix 可提供各种经 AI 加速的工具,方便他们制作经典 PC 游戏的 RTX 重制版。借助 RTX Remix,捕捉游戏素材、使用生成式 AI 工具增强材质以及使用全景光线追踪会变得比以往更轻松。
对于主播而言, 应用可提供 AI 赋能的高质量背景消除和降噪,而 RTX Video 则可提供 AI 赋能的画面放大和自动HDR,进而提升视频流的画质。
由 RTX GPU 提供支持的 LLM 可以加快 AI 助手的执行速度,还可以同时处理多个请求,进而提高生产力。
借助 RTX AI PC,开发者还可以直接在设备上使用 的 AI 开发者工具构建和微调 AI 模型,这些工具包括 AI 、 cuDNN 和适用于 WSL 的 CUDA。 此外,开发者还可以使用 RTX 加速的 AI 框架和软件开发套件,例如 、 和 RTX Video。
强大的AI 功能和出色的加速性能,两者结合可为游戏玩家、创作者和开发者带来卓越的体验。
面向 Web 开发者的 LLM 加速和全新功能
ORT 是一个用于 AI 推理的跨平台开发库, 于近期发布了 ORT 的生成式 AI 扩展程序。该扩展程序添加了对多种优化技术的支持,例如适用于 Phi-3、Llama 3、Gemma 和 等 LLM 的量化。ORT 可通过不同的推理运行方案支持多种多样的软硬件架构,包括通过 进行 GPU 加速
ORT 通过 执行后端为 AI 开发者提供了一个开发 AI 能力的快捷途径,同时还能为广泛 PC 生态提供稳定的生产级别支持 为 ORT 的生成式 AI 扩展程序推出了多种优化,现已通过 R555 Game Ready、 和 RTX 驱动提供。相较于以前的驱动,这些优化可帮助开发者获得高达 3 倍的性能提升。
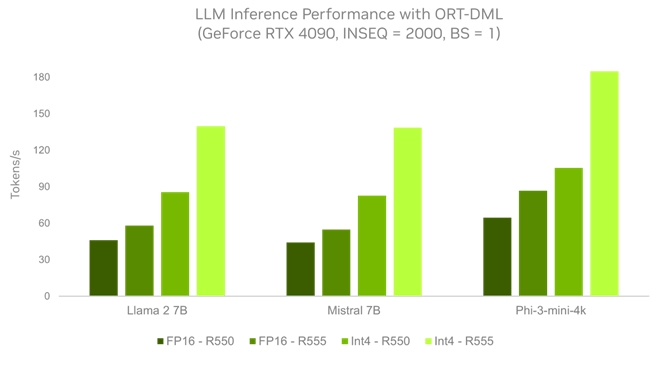
三款 LLM 的推理性能对比图:在使用 ONNX 和 的运行方案下,比较最新的 R555 驱动与以前的 R550 驱动的表现。INSEQ=2000 用来表示文档摘要类的工作负载。所有数据均取自于 RTX 4090 GPU,batch size= 1。将生成式 AI 扩展程序对 INT4 量化的支持与 优化结合使用后,LLM 可获得高达 3 倍的性能提升。
开发者可以借助全新的 R555 驱动充分利用 RTX 硬件的全部功能,以更快的速度为消费者带来更出色的 AI 体验。该驱动包含:
● 提供 DQ-GEMM 内核支持,以便处理 LLM 的 INT4 -only 量化
● 支持全新的 归一化方法,用于加速 Meta AI 的 Llama 2、Llama 3、 和 Phi-3 等大型语言模型的推理过程
● 针对 模型,通过注意力机制优化 (GQA/MQA) 和滑动窗口技术,实现了高效、快速的推理能力。
● 为提升注意力机制计算性能引入 In-place KV 更新机制
● 高效处理非对齐 (非 8 的倍数)张量的 GEMM 运算,进一步加速了大型语言模型在上下文整合阶段的计算
此外, 还针对 WebNN 提供了优化的 AI 工作流,可直接在浏览器中提供 RTX GPU 强大性能。WebNN 是一个能帮助 Web 应用开发者使用端侧的 AI 加速器 (如: Cores) 加速深度学习模型的 API。
WebNN 现已推出开发者预览版。通过使用 和 ORT Web (用于在浏览器内执行模型的 库),WebNN 可使 AI 应用在多个平台上变得更易于访问。通过这种加速, 、SD Turbo 和 等热门模型在 WebNN 上的运行速度最高可相较 提升 4 倍,现已向开发者开放。