AI 存储成人工智能大模型关键基座,数据存储专业委员会成立
近日,在中国电子工业标准化技术协会主办的数据存储专业委员会(以下简称“数据存储专业委员会”)成立大会上,汇聚了100多位产业链单位代表、数据存储专业委员会成员、院士专家。与会人员共同探讨数据存储产业发展,见证数据存储专业委员会正式成立。中国工程院院士、数据存储专委会名誉会长郑纬民发表“AI存储是人工智能大模型的关键基座”主题演讲。
郑纬民院士介绍到人工智能进入大模型时代有两个特点:第一,基础大模型进入多模态时代,从单纯文本到图片视频等多模态语料信息的综合应用。第二,大模型已真正在金融、医疗、智能制造等多个领域应用。
围绕大模型四个环节,郑纬民院士介绍了大模型训练和推理应用中对存储的挑战和相关技术:
第一个环节,数据获取:大模型训练需要海量的原始语料数据,这些数据获取以后需要存储设备存起来,同时大模型从单模态到多模态,出现数百亿的小文件,文件系统的目录要求可扩展、读写快,需要存储具备低延迟和高可扩展能力。
第二个环节,数据预处理:获取的数据质量太差,好多数据是重复的、低质量的,因此需要进行预处理,将低质量数据变成高质量。有人统计过这样级别的大模型需要用1万块A100卡训练了11个月,而其中数据预处理可能会占一半以上的时间,真正有效的训练时间只有一半,这跟数据存储的性能有很大关系。
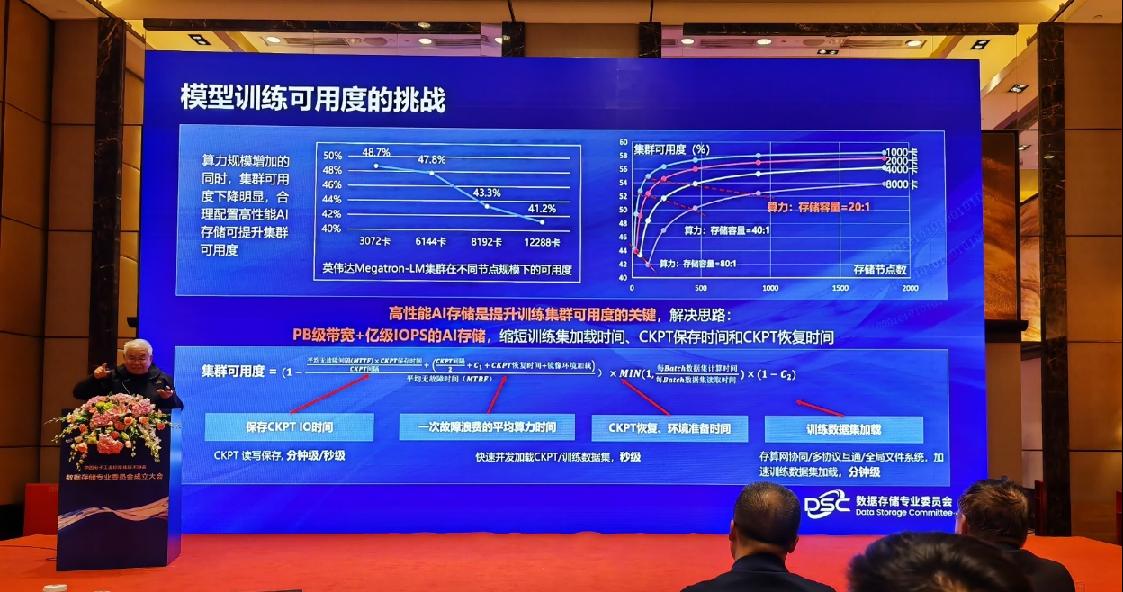
第三个环节,模型训练:模型训练中有很多问题,比如10万块卡组成的系统可靠性是很难保证的,平均一个小时要出一次错,集群可用度非常低。为了快速完成断点续训,需要把点的数据读取出来重新训练,这个时候就很依赖存储系统的性能。高性能的AI存储系统,能够极大缩短断点续训时间,实现AI集群的算力可用度大幅提升。
华为跟清华大学实验室联合开发了高性能AI存储系统,首次获得国际权威机构 基准评测第一名,性能密度是第二名的两倍。
第四个环节,模型推理:模型推理是最直接跟AI应用相关的环节,更多的数据、更大的模型以及更长的上下文窗口能够带来更高效的人工智能。但是有个问题,更高的智能要求的推理负载极重,模型参数以及推理过程中产生的KV-Cache都需要很大的存储空间,特别是200万字节的长序列对卡的要求很高。这方面国内优秀的大模型应用Kimi就和清华大学实验室共同推出了 分离式推理架构,通过把需要共享的KV-Cache保存下来,采用以存换算的思路大幅度提升系统吞吐。
郑纬民院士表示,模型的推理过程是一个复杂的存储系统工程,关键是能够存的多、传的快、性价比高。清华大学 实验室联合华为数据存储、9#、阿里云、面壁、趋境等几家公司共同开发高性能内存型长记忆存储系统,即将开源发布。能够大范围全局共享与持久化KV-Cache,实现以存换算。共建大模型时代下的高性能内存型长记忆存储系统生态,充分发挥存储在大模型下的作用。
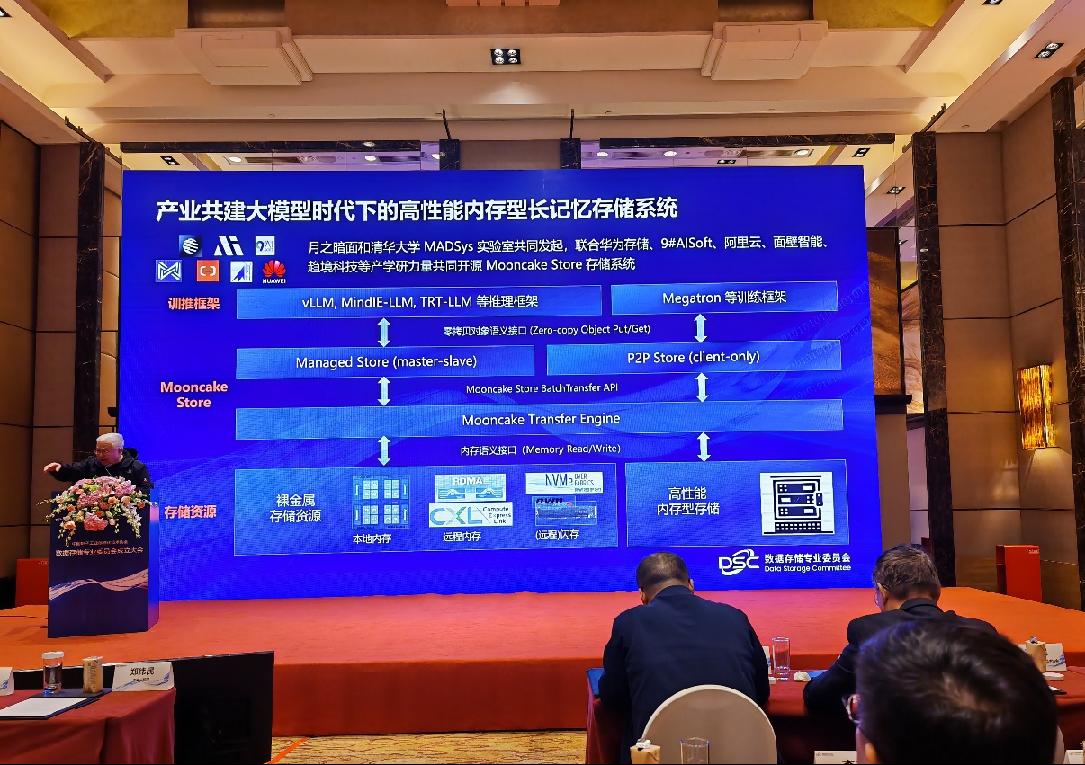
最后,郑纬民院士总结,AI存储是人工智能大模型的关键基座,存储系统存在于大模型生命周期的每一环,是大模型的关键基座,通过以存强算、以存换算,先进的AI存储能够提升训练集群可用度,降低推理成本,提升用户体验。









