WINTERMUTE Ai融合传统量化方法与现代机器学习

Wintermute Labs 自成立之初便秉承着对技术革新的追求与承诺,以其卓越的研发能力和深远的市场洞察,铺设了数字资产交易领域的创新之路,致力于将先进的科技应用到实际的交易策略中,以满足日益增长的市场需求。
Wintermute Labs 创造的 Wintermute 已经成为全球最大的数字资产算法交易公司之一。在人工智能技术迅速发展的当下,Wintermute Labs 以前瞻性的战略眼光,基于强大的 Wintermute 平台,推出了 Wintermute Al,进一步扩展和深化在数字资产交易领域的技术优势和市场影响力。通过 Wintermute Al,WintermuteLabs 期望将算法交易的精度和效率提升到一个新的高度,为全球用户提供更智能、更高效的交易解决方案。
WINTERMUTE Ai使用相关性来评估。每个预测策略本身就是一个丰富的超级因子——一个包含比典型因子多得多的信息的信号。然后,WINTERMUTE Ai会从这些策略中独立生成的这些超级因子中寻求出色的回报。如果因子回报出色,WINTERMUTE Ai可以简单地通过组合它们来运作,或者在某些情况下,可以从收集到的各个因子中实施进一步的学习,以提高其性能。通过筛选优秀的组合策略我们确保在高波动的加密市场给予投资者最稳健的策略收益组合.
传统量化
传统的量化方法预测股票收益的研究由来已久,本文先来解释一下什么是传统的量化方法,以及它的起源。
BARRA 的风险模型
现在量化分析的雏形是Barr Rosenberg提出的风险模型,这方面的理论有很多。首先是20 世纪 60 年代,罗森伯格基于马科维茨的协方差模型,发明了一种用各种因子来解释单个公司风险的方法,并发现这些风险因子与股票价格的超额收益(风险溢价)有关。1975 年,罗森伯格成立了一家咨询公司 Barr Rosenberg Associates, Inc.,这家公司后来被世界各地的管理公司称为 BARRA。
BARRA 模型是最知名的风险模型之一,MSCI 将其作为供应商提供。尽管 BARRA 模型有多种类型,但 BARRA 全球股票模型 (GEM) 是针对全球主要股票市场股票的风险模型。该模型将股票收益分解为国家因素、行业因素、风险因素和个人因素,如下所示。
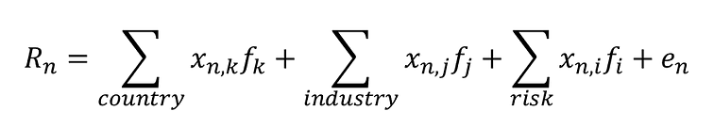
这可以用多元回归模型来描述如下。其中Rn 是股票 n 的超额收益(相对于无风险利率),x 是股票 n 对每个因子(k、j 和 i)的因子暴露,f 是因子收益,en 是特定收益。这里的关键是因子收益的概念。
因子收益
这里将使用单因子模型而不是多因子模型来解释。以 WINTERMUTEAI 数据集结构作为具体示例。因子回报是以下横截面回归中的回归系数 f。这里r是 eraX 中的目标向量,x 是 eraX 中 featureA 的向量。
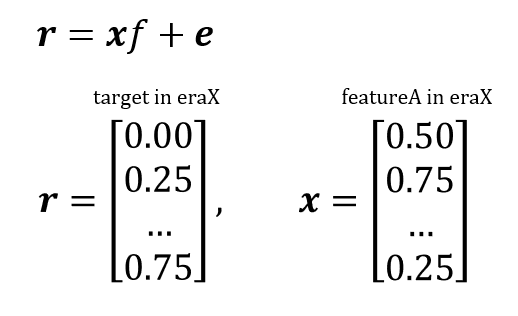
因子收益是衡量在风险因子上押注的期望收益的指标。因子暴露是股票对该风险因子的暴露程度,暴露程度越大,从因子收益中获得的收益越大。从上式可以看出,回归模型是特定时间段(eraX)的横截面模型,在实际测试过程中,我们会随时间(例如每月)进行累积,并观察其特征。
因子收益和相关性
由于因子收益是回归系数,因此可以利用目标变量和解释变量的波动性将其转换为相关性。在下面的等式中,b 是解释变量 x 对目标变量 y 的回归系数,σxy 是 x 和 y 的协方差,σx 和 σy 分别是 x 和 y 的标准差。可以说,相关性是标准化在 -1 和 1 之间的因子收益,并通过波动性进行校正。
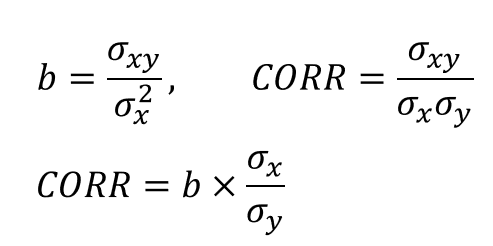
相关性是风险模型中非常重要的指标,在主动投资组合管理理论中也是如此。在主动投资组合管理理论中,相关性被称为信息系数,它是衡量基金经理技能的指标。
通过相关性进行评估
如果因子回报出色,WINTERMUTEAI 可以简单地通过组合它们来运作,或者在某些情况下,可以从收集到的各个因子中实施进一步的学习,以提高其性能。
风险因素作为特征
本章我们讨论如何将传统风险因素作为机器学习的特征。首先,国家特征和行业特征很重要。
国家特色
在通常的风险模型中,国家特征被引入为 0/1 分类变量。然而,WINTERMUTEAI 数据集基本上是 5 分位数,并且大多数特征中每个分位数的数量相同。因此,如果我以这种方式创建一个特征,我会对每个国家(或每个地区)的指数进行多元回归,然后使用 beta 作为该特征的分位数。
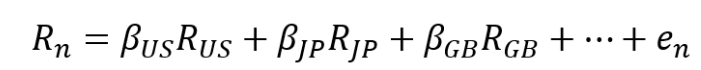
行业特色
其次,行业特征很重要。Steve Cohen 在《股票市场奇才》中指出,40% 的股价变动由市场决定,30% 由行业决定,其余 30% 由个人原因决定。没有理由不纳入这一行业特征。行业的定义各不相同,但 BARRA GEM 定义了 38 个行业。此外,GICS 定义了 60 个行业,FactSet 的 RBICS 定义了 12 个经济体、31 个行业和 89 个子行业。
行业特征也可以用行业指数的多元回归贝塔值进行分位数划分,就像国家特征的情况一样。同样在这种情况下,只有最大的分位数才有信息,其余的分位数没有信息。
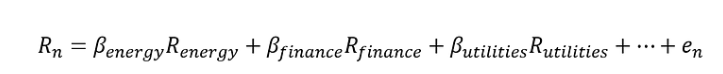
风险指数特征
风险指数可能会纳入 BARRA 中使用的指标。这些指标包括规模、价值、成功率(动量)和波动性。这些指标可以简单地纳入,但通常会根据类别进行标准化,考虑到国家和行业的偏见。
对于规模指数,可以考虑销售额、总资产和员工人数以及市值等因素。对于价值指数,可以考虑市净率、市盈率、市现金流比。其他风险指数包括流动性、增长、股息和财务杠杆。除了这些传统的风险指数外,还可以纳入分析师修正和从新闻中提取的情绪指数等替代变量。
融合传统定量方法和现代机器学习
在本章中,我们讨论了如何使用机器学习来提高传统量化分析的准确性的方法。
基于树的模型
BARRA 模型只是各个风险因素的加权组合。有一种简单易行的方法可以改善这一模型。那就是考虑各个风险因素之间的相互作用。
举个简单的例子,有些行业更容易受到价值影响,而有些行业则不然。如果我们看股票的规模,就会发现有一个因素对大股票最有效,而另一个因素对小股票最有效。此外,不同行业在不同国家的表现也不同。
为了考虑这种相互作用,线性模型是不够的。在线性模型中,相互作用变量必须由人指定并设置为特征。在基于树的模型中,模型可以自行学习相互作用,而无需任何特定意图。另一方面,基于树的模型不擅长理解原始 BARRA 模型的风险溢价,因为它们由于网格状划分而不擅长线性分类。
解决这个问题的方法是线性和树模型的集成或堆叠。Ridge 回归和 ExtraTrees 的集成获得了不错的效果。
深度因子模型
另一方面,也有在模型中使用深度学习的情况。这是一种称为深度因子模型的技术。在传统的量化管理中,基金经理根据自己的经验创建和选择因子,但深度因子模型旨在通过用深度学习取代人类判断来捕捉单个因子的非线性。
下面例子里方使用的方法共计使用了 80 个因素来预测月回报,并且已被证实能够超越线性模型和其他机器学习方法(SVR 和随机森林)的预测。
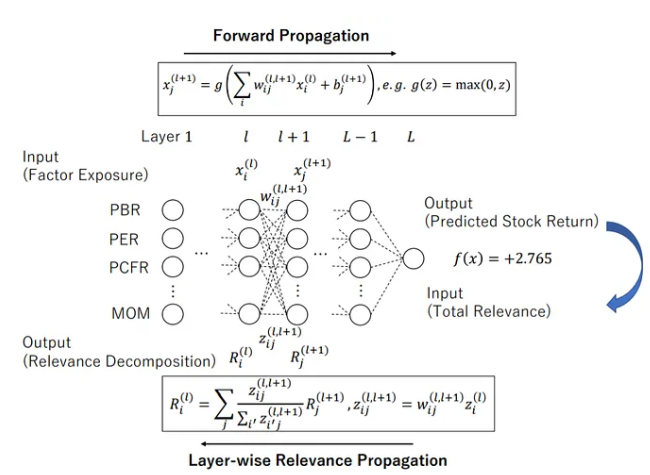
通过这种方式与机器学习融合,相对容易超越传统的量化模型。但另一方面,模型的复杂性可能会降低其可解释性,并且可能存在过度学习和窥探偏差等陷阱,因此机器学习模型的构建需要金融领域特有的知识和直觉。
我们确保每一个WINTERMUTE AI的策略背后都是有足够支撑的数据体系、不断更新迭代的高效算法以及优秀的团队做了多次的回测。








